Programming in the moderncurrent age
Published by marco on
In order to program in 2013, it is important not to waste any time honing your skills with outdated tools and work-flows. What are the essential pieces of software for developing software in 2013?
- Runtime
- A runtime is a given for all but the most esoteric of programming exercises. Without something to execute your code, there is almost no point in writing it.
- Debugger
- Programming without an integrated debugger can be very time-consuming, error-prone and will quite frankly suck the fun right out of the whole endeavor. And, by “debugger” I mean a source-level single-step debugger with call-stack and variable/object/structure inspection as well as expression evaluation. Poring through logs and inserting print statements is not a viable long-term or even medium-term solution. You shouldn’t be writing in a language without one of these unless you absolutely can’t avoid it (NAnt build scripts come to mind).
- Compiler/Checker
- A syntax/semantics checker of some sort integrated into the editor ensures a tighter feedback/error-finding loop and saves time, energy and frustration. I was deliberately cagey with the “checker” because I understand that some languages, like Javascript[1], do not have a compiled form. Duck-typed languages like Python or Ruby also limit static checking but anything is better than nothing.
- Versioning
- A source-control system is essential in order to track changes, test ideas and manage releases. A lot of time can be wasted—and effort lost—without good source control. Great source control decreases timidity, encourages experimentation and allows for interruptible work-flows. I will argue below that private branches and history rewriting are also essential.
Even for the smallest projects, there is no reason to forgo any of these tools.
Managing your Source Code
tl;dr: It’s 2013 and your local commit history is not sacrosanct. No one wants to see how you arrived at the solution; they just want to see clean commits that explain your solution as clearly as possible. Use git; use rebase; use “rebase interactive”; use the index; stage hunks; squash merge; go nuts.[2]
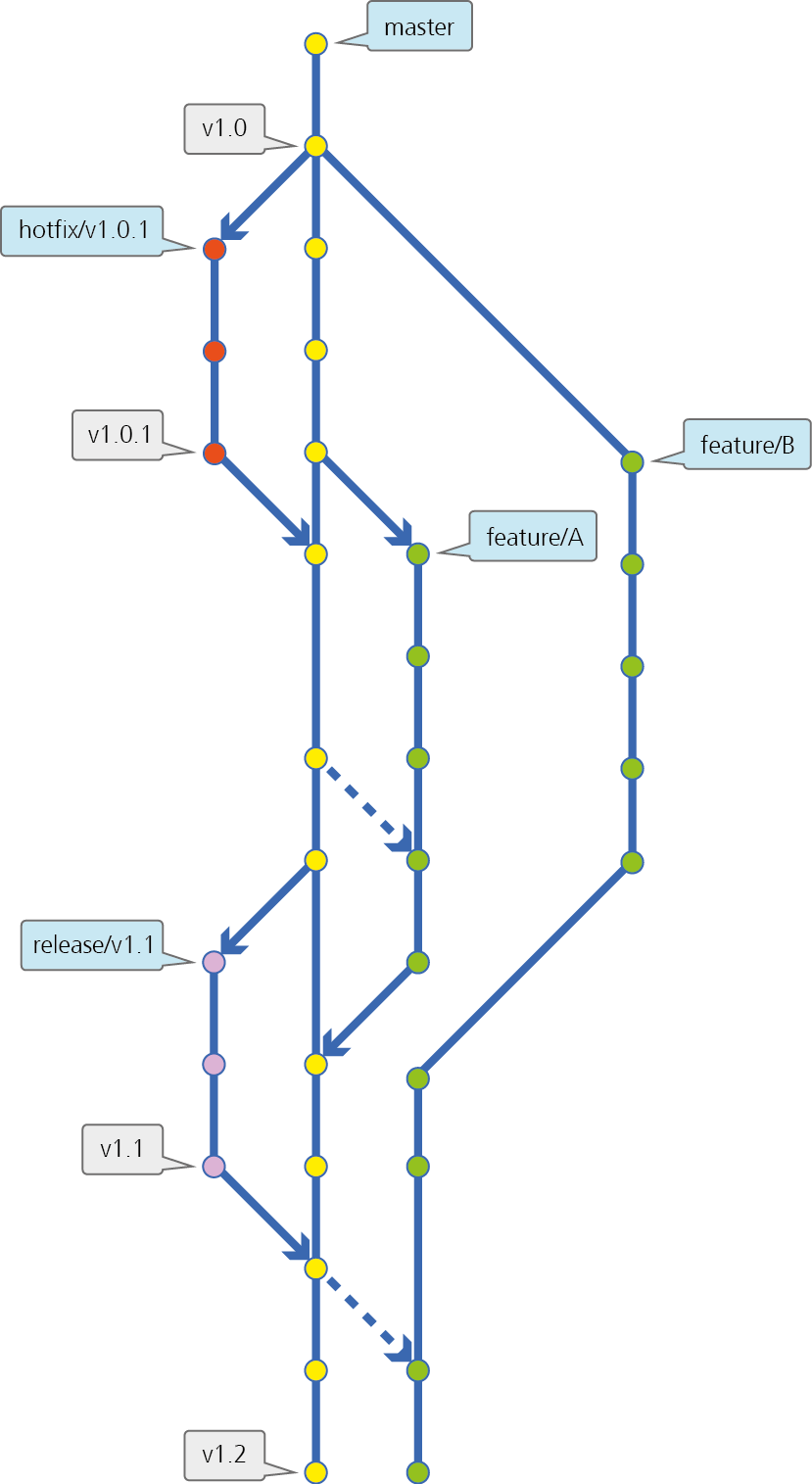 Encodo's Branching ModelI would like to focus on the “versioning” part of the tool-chain. Source control tells the story of your code, showing how it evolved to where it is at any given point. If you look closely at the “Encodo Branching Model”[3] diagram (click to enlarge), you can see the story of the source code:
Encodo's Branching ModelI would like to focus on the “versioning” part of the tool-chain. Source control tells the story of your code, showing how it evolved to where it is at any given point. If you look closely at the “Encodo Branching Model”[3] diagram (click to enlarge), you can see the story of the source code:
- All development was done in the master branch until v1.0 was released
- Work on B was started in a feature branch
- Work on hotfix v1.0.1 was started in a hotfix branch
- Work on A was started in another feature branch
- Hotfix v1.0.1 was released, tagged and merged back to the master branch
- Development continued on master and both feature branches
- Master was merged to feature branch A (includes hotfix v1.0.1 commits)
- Finalization for release v1.1 was started in a release branch
- Feature A was completed and merged back to the master branch
- Version v1.1 was released, tagged and merged back to the master branch
- Master was merged to feature branch B (includes v1.1 and feature A commits)
- Development continued on master and feature B
- Version v1.2 was released and tagged
Small, precise, well-documented commits are essential in order for others to understand the project—especially those who weren’t involved in developing the code. It should be obvious from which commits you made a release. You should be able to go back to any commit and easily start working from there. You should be able to maintain multiple lines of development, both for maintenance of published versions and for development of new features. The difficulty of merging these branches should be determined by the logical distance between them rather than by the tools. Merging should almost always be automatic.
Nowhere in those requirements does it say that you’re not allowed to lie about how you got to that pristine tree of commits.
Why you should be using private branches and history rewriting
A few good articles about Git have recently appeared—Understanding the Git Workflow by Benjamin Sandofsky is one such—explaining better than ever why rewriting history is better than server-side, immutable commits.
In the article cited above, Sandofsky divides his work up into “Short-lived work […] larger work […] and branch bankrupty.” These concepts are documented to some degree in the Branch Management chapter of the Encodo Git Handbook (of which I am co-author). I will expand on these themes below.
Note: The linked articles deal exclusively with the command line, which isn’t everyone’s favorite user interface (I, for one, like it). We use the SmartGit/Hg client for visualizing diffs, organizing commits and browsing the log. We also use the command-line for a lot of operations, but SmartGit is a very nice tool and version 3 supports nearly all of the operations described in this article.
What is rebasing?
As you can see from the diagram above, a well-organized and active project will have multiple branches. Merging and rebasing are two different ways of getting commits from one branch into another.
Merging commits into a branch creates a merge commit, which shows up in the history to indicate that n commits were made on a separate branch. Rebasing those commits instead re-applies those commits to the head of the indicated branch without a merge commit. In both cases there can be conflicts, but one method doesn’t pose a greatest risk of them than the other.[4] You cannot tell from the history that rebased commits were developed in a separate branch. You can, however, tell that the commits were rebased because the author date (the time the commit was originally created) differs from the commit date (the last time that the commit was applied).
What do you recommend?
At Encodo, we primarily work in the master branch because we generally work on very manageable, bite-sized issues that can easily be managed in a day. Developers are free to use local branches but are not required to do so. If some other requirement demands priority, we shunt the pending issue into a private branch. Such single-issue branches are focused and involve only a handful of files. It is not at all important to “remember” that the issue was developed in a branch rather than the master branch. If there are several commits, it may be important for other users to know that they were developed together and a merge-commit can be used to indicate this. Naturally, larger changes are developed in feature branches, but those are generally the exception rather than the rule.
Remember: Nowhere in those requirements does it say that you’re not allowed to lie about how you got to that pristine tree of commits.
Otherwise? Local commit history is absolutely not sacrosanct. We rebase like crazy to avoid unwanted merge commits. That is, when we pull from the central repository, we rebase our local commits on top of the commits that come form the origin. This has worked well for us.
If the local commit history is confusing—and this will sometimes come up during the code review—we use an interactive rebase to reorganize the files into a more soothing and/or understandable set of commits. See Sandofsky’s article for a good introduction to using interactive rebasing to combine and edit commits.
Naturally, we weigh the amount of confusion caused by the offending commits against the amount of effort required to clean up the history. We don’t use bisect[5] very often, so we don’t invest a lot of time in enforcing the clean, compilable commits required by that tool. For us, the history is interesting, but we rarely go back farther than a few weeks in the log.[6]
When to merge? When to rebase?
At Encodo, there are only a few reasons to retain a merge commit in the official history:
- If we want to remember which commits belonged to a particular feature. Any reasonable tool will show these commits graphically as a separate strand running alongside the master branch.
- If a rebase involves too much effort or is too error-prone. If there are a lot of commits in the branch to be integrated, there may be subtle conflicts that resolve more easily if you merge rather than rebase. Sometimes we just pull the e-brake and do a merge rather than waste time and effort trying to get a clean rebase. This is not to say that the tools are lacking or at fault but that we are pragmatic rather than ideological.[7]
- If there are merge commits in a feature branch with a large number of well-organized commits and/or a large number of changes or affected files. In this case, using a squash merge and rebuilding the commit history would be onerous and error-prone, so we just merge to avoid issues that can arise when rebasing merge commits (related to the point above).
When should I use private branches? What are they exactly?
There are no rules for local branches: you can name them whatever you like. However, if you promote a local branch to a private branch, at Encodo we use the developer’s initials as the prefix for the branch. My branches are marked as “mvb/feature1”, for example.
What’s the difference between the two? Private branches may get pushed to our common repository. Why would you need to do that? Well, I, for example, have a desktop at work and, if I want to work at home, I have to transfer my workspace somehow to the machine at home. One solution is to work on a virtual machine that’s accessible to both places; another is to remote in to the desktop at work from home; the final one is to just push that work to the central repository and pull it from home. The offline solution has the advantage of speed and less reliance on connectivity.
What often happens to me is that I start work on a feature but can only spend an hour or two on it before I get pulled off onto something else. I push the private branch, work on it a bit more at home, push back, work on another, higher-priority feature branch, merge that in to master, work on master, whatever. A few weeks later and I’ve got a private branch with a few ugly commits, some useful changes and a handful of merge commits from the master branch. The commit history is a disgusting mess and I have a sneaking suspicion that I’ve only made changes to about a dozen files but have a dozen commits for those changes.
That’s where the aforementioned “branch bankruptcy” comes in. You’re not obligated to keep that branch; you can keep the changes, though. As shown in the referenced article, you execute the following git commands:
git checkout master
git checkout -b cleaned_up_branch
git merge --squash private_feature_branch
git resetThe --squash tells git to squash all of the changes from the private_feature_branch into the index (staging) and reset the index so that those changes are in the working tree. From here, you can make a single, clean, well-written commit or several commits that correspond logically to the various changes you made.
Git also lets you lose your attachment to checking in all the changes in a file at once: if a file has changes that correspond to different commits, you can add only selected differences in a file to the index (staging). In praise of Git’s index by Aristotle Pagaltzis (Plasmasturm) provides a great introduction. If you, like me, regularly take advantage of refactoring and cleanup tools while working on something else, you’ll appreciate the ability to avoid checking in dozens of no-brainer cleanup/refactoring changes along with a one-liner bug-fix.[8]
One final example: cherry picking and squashing
I recently renamed several projects in our solution, which involved renaming the folders as well as the project files and all references to those files and folders. Git automatically recognizes these kind of renames as long as the old file is removed and the new file is added in the same commit.
I selected all of the files for the rename in SmartGit and committed them, using the index editor to stage only the hunks from the project files that corresponded to the rename. Nice and neat. I selected a few other files and committed those as a separate bug-fix. Two seconds later, the UI refreshed and showed me a large number of deleted files that I should have included in the first commit. Now, one way to go about fixing this is to revert the two commits and start all over, picking the changes apart (including playing with the index editor to stage individual hunks).
Instead of doing that, I did the following:
- I committed the deleted files with the commit message “doh!” (to avoid losing these changes in the reset in step 3)
- I created a “temp” branch to mark that commit (to keep the commit visible once I reset in step 3)
- I hard-reset my master branch to the origin
- I cherry-picked the partial-rename commit to the workspace
- I cherry-picked the “doh!” commit to the workspace
- Now the workspace had the rename commit I’d wanted in the first place
- I committed that with the original commit message
- I cherry-picked and committed the separate bug-fix commit
- I deleted the “temp” branch (releasing the incorrect commits on it to be garbage-collected at some point)
Now my master branch was ready to push to the server, all neat and tidy. And nobody was the wiser.
[1] There are alternatives now, though, like Microsoft’s TypeScript, that warrant a look if only because they help tighten the error-finding feedback loop and have the potential to make you more efficient (the efficiency may be robbed immediately back, however, if debugging generated code becomes difficult or even nightmarish).↩
[2] Once you’ve pushed, though? No touchie. At that point, you’ve handed in your test and you get graded on that.↩
[4] With the exception, mentioned elsewhere as well, that rebasing merge-commits can sometimes require you to re-resolve previously resolved conflicts, which can be error-prone if the conflicts were difficult to resolve in the first place. Merging merge-commits avoids this problem.↩
[5]
bisect is a git feature that executes a command against various commits to try to localize the commit that caused a build or test failure. Basically, you tell it the last commit that worked and git uses a binary search to find the offending commit. Of course, if you have commits that don’t compile, this won’t work very well. We haven’t used this feature very much because we know the code in our repositories well and using blame and log is much faster. Bisect is much more useful for maintainers that don’t know the code very well, but still need to figure out at which commit it stopped working.↩[6] To be clear: we’re only so cavalier with our private repositories to which access is restricted to those who already know what’s going on. If we commit changes to public, open-source or customer repositories, we make sure that every commit compiles. See Aristotle’s index article (cited above) for tips on building and testing against staged files to ensure that a project compiles, runs and passes all tests before making a commit—even if you’re not committing all extant changes.↩
[7] That said, with experience we’ve learned that an interactive rebase and judicious squashing will create commits that avoid these problems. With practice, these situations crop up more and more rarely.↩
[8] Of course, you can also create a separate branch for your refactoring and merge it all back together, but that’s more work and is in my experience rarely necessary.↩