Profiling: that critical 3% (Part II)
Published by marco on
 In part I of this series, we discussed some core concepts of profiling. In that article, we not only discussed the problem at hand, but also how to think about not only fixing performance problems, but reducing the likelihood that they get out of hand in the first place.
In part I of this series, we discussed some core concepts of profiling. In that article, we not only discussed the problem at hand, but also how to think about not only fixing performance problems, but reducing the likelihood that they get out of hand in the first place.
In this second part, we’ll go into detail and try to fix the problem.
Reëvaluating the Requirements
Since we have new requirements for an existing component, it’s time to reconsider the requirements for all stakeholders. In terms of requirements, the IScope can be described as follows:
- Hold a list of objects in LIFO order
- Hold a list of key/value pairs with a unique name as the key
- Return the value/reference for a key
- Return the most appropriate reference for a given requested type. The most appropriate object is the one that was added with exactly the requested type. If no such object was added, then the first object that conforms to the requested type is returned
- These two piles of objects are entirely separate: if an object is added by name, we do not expect it to be returned when a request for an object of a certain type is made
There is more detail, but that should give you enough information to understand the code examples that follow.
Usage Patterns
There are many ways of implementing the functional requirements listed above. While you can implement the feature with only requirements, it’s very helpful to know usage patterns when trying to optimize code.
Therefore, we’d like to know exactly what kind of contract our code has to implement—and to not implement any more than was promised.
Sometimes a hopeless optimization task gets a lot easier when you realize that you only have to optimize for a very specific situation. In that case, you can leave the majority of the code alone and optimize a single path through the code to speed up 95% of the calls. All other calls, while perhaps a bit slow, will at least still be yield the correct results.
And “optimized” doesn’t necessarily mean that you have to throw all of your language’s higher-level constructs out the window. Once your profiling tool tells you that a particular bit of code has introduced a bottleneck, it often suffices to just examine that particular bit of code more closely. Just picking the low-hanging fruit will usually be more than enough to fix the bottleneck.[1]
Create scopes faster[2]
I saw in the profiler that creating the ExpressionContext had gotten considerably slower. Here’s the code in the constructor.
foreach (var value in values.Where(v => v != null))
{
Add(value);
}I saw a few potential problems immediately.
- The call to
Add()had gotten more expensive in order to return the most appropriate object from theGetInstances()method - The Linq replaced a call to
AddRange()
The faster version is below:
var scope = CurrentScope;
for (var i = 0; i < values.Length; i++)
{
var value = values[i];
if (value != null)
{
scope.AddUnnamed(value);
}
}Why is this version faster? The code now uses the fact that we know we’re dealing with an indexable list to avoid allocating an enumerator and to use non-allocating means of checking null. While the Linq code is highly optimized, a for loop is always going to be faster because it’s guaranteed not to allocate anything. Furthermore, we now call AddUnnamed() to use the faster registration method because the more involved method is never needed for these objects.
The optimized version is less elegant and harder to read, but it’s not terrible. Still, you should use these techniques only if you can prove that they’re worth it.
Optimizing CurrentScope
Another minor improvement is that the call to retrieve the scope is made only once regardless of how many objects are added. On the one hand, we might expect only a minor improvement since we noted above that most use cases only ever add one object anyway. On the other, however, we know that we call the constructor 20 million times in at least one test, so it’s worth examining.
The call to CurrentScope gets the last element of the list of scopes. Even something as innocuous as calling the Linq extension method Last() can get more costly than it needs to be when your application calls it millions of times. Of course, Microsoft has decorated its Linq calls with all sorts of compiler hints for inlining and, of course, if you decompile, you can see that the method itself is implemented to check whether the target of the call is a list and use indexing, but it’s still slower. There is still an extra stack frame (unless inlined) and there is still a type-check with as.
Replacing a call to Last() with getting the item at the index of the last position in the list is not recommended in the general case. However, making that change in a provably performance-critical area shaved a percent or two off a test run that takes about 45 minutes. That’s not nothing.
protected IScope CurrentScope
{
get { return _scopes.Last(); }
}protected IScope CurrentScope
{
get { return _scopes[_scopes.Count − 1]; }
}That takes care of the creation & registration side, where I noticed a slowdown when creating the millions of ExpressionContext objects needed by the data driver in our product’s test suite.
Get objects faster
Let’s now look at the evaluation side, where objects are requested from the context.
The offending, slow code is below:
public IEnumerable<TService> GetInstances<TService>()
{
var serviceType = typeof(TService);
var rawNameMatch = this[serviceType.FullName];
var memberMatches = All.OfType<TService>();
var namedMemberMatches = NamedMembers.Select(
item => item.Value
).OfType<TService>();
if (rawNameMatch != null)
{
var nameMatch = (TService)rawNameMatch;
return
nameMatch
.ToSequence()
.Union(namedMemberMatches)
.Union(memberMatches)
.Distinct(ReferenceEqualityComparer<TService>.Default);
}
return namedMemberMatches.Union(memberMatches);
}As you can readily see, this code isn’t particularly concerned about performance. It is, however, relatively easy to read and to figure out the logic behind returning objects, though. As long as no-one really needs this code to be fast—if it’s not used that often and not used in tight loops—it doesn’t matter. What matters more is legibility and maintainability.
But we now know that we need to make it faster, so let’s focus on the most-likely use cases. I know the following things:
- Almost all
Scopeinstances are created with a single object in them and no other objects are ever added. - Almost all object-retrievals are made on such single-object scopes
- Though the scope should be able to return all matching instances, sorted by the rules laid out in the requirements, all existing calls get the
FirstOrDefault()object.
These extra bits of information will allow me to optimize the already-correct implementation to be much, much faster for the calls that we’re likely to make.
The optimized version is below:
public IEnumerable<TService> GetInstances<TService>()
{
var members = _members;
if (members == null)
{
yield break;
}
if (members.Count == 1)
{
if (members[0] is TService)
{
yield return (TService)members[0];
}
yield break;
}
object exactTypeMatch;
if (TypedMembers.TryGetValue(typeof(TService), out exactTypeMatch))
{
yield return (TService)exactTypeMatch;
}
foreach (var member in members.OfType<TService>())
{
if (!ReferenceEquals(member, exactTypeMatch))
{
yield return member;
}
}
}Given the requirements, the handful of use cases and decent naming, you should be able to follow what’s going on above. The code contains many more escape clauses for common and easily handled conditions, handling them in an allocation-free manner wherever possible.
- Handle empty case
- Handle single-element case
- Return exact match
- Return all other matches[3]
You’ll notice that returning a value added by-name is not a requirement and has been dropped. Improving performance by removing code for unneeded requirements is a perfectly legitimate solution.
Test Results
And, finally, how did we do? I created tests for the following use cases:
- Create scope with multiple objects
- Get all matching objects in an empty scope
- Get first object in an empty scope
- Get all matching objects in a scope with a single object
- Get first object in a scope with a single object
- Get all matching objects in a scope with multiple objects
- Get first object in a scope with multiple objects
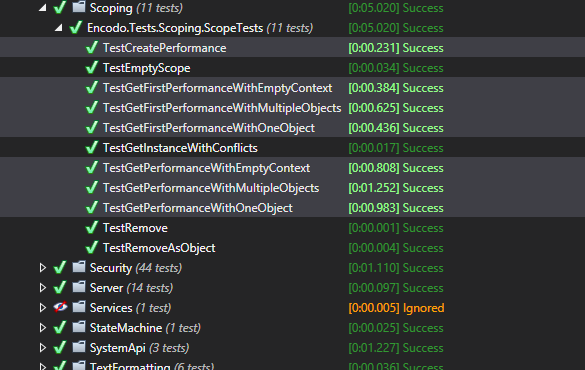
Here are the numbers from the automated tests.
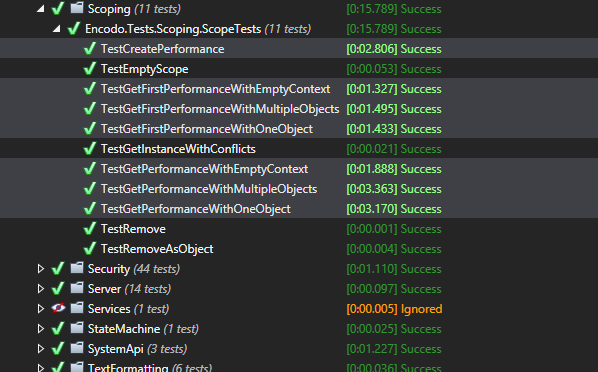
- Create scope with multiple objects — 12x faster
- Get all matching objects in an empty scope — almost 2.5x faster
- Get first object in an empty scope — almost 3.5x faster
- Get all matching objects in a scope with a single object — over 3x faster
- Get first object in a scope with a single object — over 3.25x faster
- Get all matching objects in a scope with multiple objects — almost 3x faster
- Get first object in a scope with multiple objects — almost 2.25x faster
This looks amazing but remember: while the optimized solution may be faster than the original, all we really know is that we’ve just managed to claw our way back from the atrocious performance characteristics introduced by a recent change. We expect to see vast improvements versus a really slow version.
Since I know that these calls showed up as hotspots and were made millions of times in the test, the performance improvement shown by these tests is enough for me to deploy a pre-release of Quino via TeamCity, upgrade my product to that version and run the tests again. Wish me luck![4]
[1] Or, most likely, push it to some other piece of code.↩
[2] The best approach at this point is to create issues for the other performance investigations you could make. For example, I opened an issue called Optimize allocations in the data handlers (start with IExpressionContexts), documented everything I had analyzed and quickly got back to the issue on which I’d started.↩
[3] For those with access to the Quino Git repository, the diffs shown below come from commit a825d5030ce6f65a452e1db85a308e1351288b96.↩
[4] If you’re following along very, very carefully, you’ll recall at this point that the requirement stated above is that objects are returned in LIFO order. The faster version of the code returns objects in FIFO order. You can’t tell that the original, slow version did guarantee LIFO ordering, but only because the call to get
All members contained a hidden call to the Linq call Reverse(), which slowed things down even more! I removed the call to reverse all elements because (A) I don’t actually have any tests for the LIFO requirement nor (B) do I have any other code that expects it to happen. I wasn’t about to make the code even more complicated and possibly slower just to satisfy a purely theoretical requirement. That’s the kind of behavior that got me into this predicament in the first place.↩[5] Spoiler alert: it worked. ;-) The fixes cut the testing time from about 01:30 to about 01:10 for all tests on the build server, so we won back the lost 25%.↩