Links and Notes for May 16th, 2025
Below are links to articles, highlighted passages[1], and occasional annotations[2] for the week ending on the date in the title, enriching the raw data from Instapaper Likes and Twitter. They are intentionally succinct, else they’d be articles and probably end up in the gigantic backlog of unpublished drafts. YMMV.
[1] Emphases are added, unless otherwise noted.↩
[2] Annotations are only lightly edited and are largely contemporaneous.↩
Table of Contents
- Public Policy & Politics
- Journalism & Media
- Economy & Finance
- Environment & Climate Change
- Art, Literature, & Cinema
- Philosophy, Sociology, & Culture
- Technology & Engineering
- LLMs & AI
- Programming
Public Policy & Politics
The Battle Of Tandoori Chicken by Indrajit Samarajiva (Indica)
“This is not to say that India can’t cause significant damage to Pakistan, but in these conditions they cannot achieve air superiority, which is the only context imperial weapons systems are designed for. As Laurie Buckhout, former chief of the US Army’s electronic warfare division, said “Our biggest problem is we have not fought in a comms-degraded environment for decades, so we don’t know how to do it. We lack not only tactics, techniques and procedures but the training to fight in a comms-degraded environment.””
“The White Empire cannot train or equip anyone for situations they themselves are not trained or equipped for. For decades they’ve grown fat bombing hospitals and looting their own allies and cannot move under actual fire. All of these fancy, interconnected systems are designed for bombing people without air defenses, not people with functional air defenses and, God-forbid, offenses of their own.”
“Also remember that quantity is its own quality, and China has both. In light drones, for example, China produces the best and the most, though they only show them for light shows. Imagine a Chinese drone swarm, it would be terrifying. Or look at the production process of the PL-15 missile, it’s almost completely automated and can run 24 hours. This is unstoppable.”
Germany’s New Chancellor Is a Man Without Qualities by Dominik A. Leusder (Jacobin)
“Merz chose to wrangle the corpse of the outgoing Bundestag, which reflected the election results of 2021, into a dirty compromise with the Green Party. In the chancellor’s view then, democratic backsliding is a worthy price to pay in exchange for disenfranchising the political left.”
“A bland creature of the conservative wing of the business community, Merz lacks the intellectual and political resources to steer a large trading economy through a dual-front trade rivalry with the United States and China.”
“But Germany won’t avoid a “second China shock” by simply appeasing the anti-immigrant sentiments of the German far right. Only a wholesale retreat from an exhausted and intellectually derelict geopolitical and economic policy framework stands a chance of securing a prosperous future for the country. Merz, in many ways the last gasp of German neoliberalism, is woefully unequipped to do so.”
The Price of Silence: Gaza’s Famine and the Erosion of Our Humanity − Politics For The People by Ramzy Baroud (ZNetwork)
“Despite this, hope persists that fundamental human compassion, separate from legal frameworks, will compel the provision of essential supplies like flour, sugar, and water to Gaza. The inability to ensure this basic aid will profoundly question our shared humanity for years to come.”
What’s the f&@king point if the bombing and ethnic cleansing don’t end?
Nobody’s questioning it, if we’re honest. The number of people who are questioning anything are a rounding error. The nicest and smartest people in the West are over here lamenting the end of the rules-based order without having once even questioned the legitimacy of the empire to call itself that. They fervently wish things would go back to the way they were—that is, they lament not the violence, genocide, or starving people, they lament that it’s become more a tiny bit more work to convince themselves that they’re morally righteous. The cognitive dissonance is a wee bit higher, so they are kind of upset about that. In the past, the narrative was simpler, more straightforward. Now they feel a bit discomfited about things and they wish that all of these disturbing and intrusive thoughts would go away so that they could go back to focusing on their pension funds, their careers, and their second homes without even a hint of a ripple on the lakes of their consciences.
Extended interview: Norman Finkelstein REACTS To Israeli Embassy Shooting by Useful Idiots (YouTube)
At about 23:00, you can hear congressman Randy Fine calling for the nuclear bombing of Arab culture. These people are unhinged. And they’re interviewed on national news in the U.S. and no questions a single thing they say. No-one calls them monsters for even thinking something like that, to say nothing of publicly advocating the position as a sitting member of the legislative body that is allowed observe the operation of the empire.
Finkelstein’s response puts these statements—and those of Israeli officials—into historical context.
“There was a very good book written, probably about 30 years ago now, by a fellow named John Dowers. It was called war without mercy and it was a description of the kinds of language, public presentation, during the US war with Japan. And it was on both sides: the Japanese demonizing to the point of satanic description of the US—meaning everyone in the US—and the US doing the same thing with the Japanese. If you read the the book, it’s very, very ugly how the US depicted the Japanese. The attitudes towards the tortures of Japanese, the glee at, for example, the incineration of Tokyo during World War II. I mean glee. [you saw this a bit in the film Oppenheimer.]
“Then, if you read about our own Indian wars—as they were called—the kinds of insanity that came out of very respected figures. Even, in retrospect, if you read Theodore Roosevelt’s The Winning of the West—it’s a five-volume work he wrote—and his descriptions of Native Americans will make your skin crawl.
“So, in that respect, you can’t say Israel is completely aberrant in the broad history. These kinds of psychopathic outbursts are not unusual, especially after October 7th, where kind-of all the demons in Israeli society, which, for one reason or another, they had to repress or suppress…all the demons rose to the surface and all of the ugliness of that society.
“They felt they now, after October 7th, they had license—they had moral license—to publicly espouse—I think a lot of it was repressed; it was there if you scratch the surface. With any Israeli, their loathing and contempt for Arabs in general—and Gazans in particular—it was there. But there was always—it’s a western country, so there was a veneer of being civilized—and what October 7th did was, it enabled the Israelis to free themselves from that veneer and for all the demons to rise to the surface.
“Israelis, unlike Nazi Germany, they don’t have the pretense or the pretext that they didn’t know what was happening.
“[…]
“It’s a national project. Israel doesn’t have a citizen army. It’s representative of the cross-section of Israeli society. The people carrying on the genocide are representative of—anchored in—Israeli society. If it’s not the person him or herself, it’s an uncle, it’s a father, it’s a brother, it’s a son, a daughter [contributed by Katie], they all know. They all approve. Every poll taken since October 7th has shown that roughly 95% of Israelis believe, knowing full well what’s going on. 95% believe that Israel is using enough or too little force in Gaza. 40% think Israel is—Jewish Israelis believe that Israel is—not using using enough force in Gaza.
“[…]
“I have to be sensitive to other historical examples I’ve seen. For example, the US with Japan, the US during the Indian wars. On the other hand, I do think that—at least in the
current world, let’s say since World War II—this is in a class all its own for many reasons. I mean, the sheer numbers since the 21st century—the last 25 years—it’s unique in every category. There’s just nothing like it. If you use any metric—any metric whatsoever—this falls into a totally different category, what Israel is doing in Gaza.”
There follows a long and interesting conversation about the degree to which universities in the U.S.—anywhere, really—should allow students to matriculate who have been involved in war crimes. Specifically, the U.S. seems to think that Israeli students who have served in the IDF should get more protection, whereas the moral case is that anyone who has participated in executing a genocide and holocaust should be shunned.
Their own country and society can welcome them and care for them—as they’d committed the war crimes for that country—but no other country has that obligation. Especially since they’ve not actually been punished for their crimes. I believe that once someone has been judged, sentenced, and served their sentence, that we should consider that debt to society paid. Depending on what they’ve done, forgiveness is more or less difficult. But these criminals not only have gone completely unpunished, but are rewarded with preferential treatment at U.S. universities, where their precious feelings about being called war criminals and murderers are paramount. It’s madness.
Cycles of violence by Yasha Levine (Nefarious Russians)
He cites at length from Elias Rodriguez’s last message.
“Never before had so many American politicians been forced to concede that, rhetorically at least, the Palestinians were human beings, too. But thus far the rhetoric has not amounted to much. The Israelis themselves boast about their own shock at the free hand the Americans have given them to exterminate the Palestinians. Public opinion has shifted against the genocidal apartheid state, and the American government has simply shrugged, they’ll do without public opinion then, criminalize it where they can, suffocate it with bland reassurances that they’re doing all they can to restrain Israel where it cannot criminalize protest outright.”
“Elsewhere a man of conscience once attempted to throw Robert McNamara off a Martha’s Vineyard-bound ferry into the sea, incensed at the same impunity and arrogance he saw in that butcher of Vietnam as he sat in the ferry’s lounge laughing with friends. The man took issue with McNamara’s “very posture, telling you, ‘My history is fine, and I can be slumped over a bar like this with my good friend Ralph here and you’ll have to lump it.‘””
“[…] inhumanity has long since shown itself to be shockingly common, mundane, prosaically human. A perpetrator may then be a loving parent, a filial child, a generous and charitable friend, an amiable stranger, capable of moral strength at times when it suits him and sometimes even when it does not, and yet be a monster all the same. Humanity doesn’t exempt one from accountability.”
Journalism & Media
Ode to Scum by Matt Taibbi (Racket News)
“That was not because I liked Trump or even thought much about him, but because I didn’t see this as a normal electoral battle. Instead, I saw institutional elites unifying to rub out an irksome voter revolt. This was an extension of a disagreement I’d long had about campaign reporting. I’d covered races since 2004 and long before Trump arrived concluded the purpose of each agonizing two-year campaign of primaries, polls, debates, endorsements, Jefferson-Jackson dinners, scandals, and cable nerf-battles was to prevent establishment-unacceptable candidates (Ron Paul, Dennis Kucinich, etc.) from breaking through. The ritual the Daily Show called “Clusterf**k to the White House” was a PR snow job, designed to convince liberals opposing war was impractical and that organized labor didn’t need to support labor candidates, while conservatives were propagandized to stop wondering why their own politicians kept expanding government. The campaign press was like an immune system, there to badger to death anything off-message, even a gently antiwar run by Howard Dean.
“The end goal of the show was to eliminate real politics and secure matchups like Folksy v. Wonky (Bush v. Gore), Yale v. Yale (Bush v. Kerry) or the media’s favorite, Kennedyesque v. Reaganesque (Any Democrat v. Any Republican). Races rarely saw substantive choice on that year’s chief issue (the 2004 election for instance let us pick between two Iraq War supporters). The reason I have such a long history of trashing both parties (my first book here was called Spanking the Donkey) is because I never saw them as antagonists, but as factions of the same establishment whole. They differed on minor issues while pledging continuity on major ones like war, NATO, the Fed, bailouts, criminal justice disparities, etc.”
“I never saw Trump as a politician. He was a screeching shit-monster catapulted from hell at America’s Deserving Class. When he won last Election Night it was like watching Godzilla march through an Americanized Tokyo, squashing subway cars full of screaming MSNBC producers, stepping on the lawyers in smart glasses and Tumi bags running in terror from White & Case or Covington & Burling offices, then rearing back to send a fat blue streak of irradiated death through crowds of fleece-wearing male “allies,” Jen Psaki, and a vanishing, Japanesed Adam Schiff. Apparently now Trumpzilla’s off stomping on other things, from Harvard to Oprah to bar codes. I can absolutely think this is funny, and that most deserve this, without endorsing it.
“Opponents and pundits endlessly compared Trump to Hitler but the real historical analog has always been Napoleon. Through insults to Popes and Kings he united every aristocratic faction in Europe to the point where after Waterloo, he was removed to an island in the middle of the ocean so he could no longer “disturb the peace of the world.” That was the world goal for Trump, whose similar crime was called “undermining the rules-based international order.” It’s mind-boggling how quickly “heterodox” thinkers have forgotten how ruthless, far-reaching, and authoritarian this campaign to remove the Trumpian tumor was and is. The clear endgame of speech-control laws in Europe and the aggressive moves to disqualify candidates in places like Romania and even France was to put a digital lid on nationalism and populism, and confine them to a cyber version of Napoleon’s last home on St. Helena.
“I’m absolutely against throwing Öztürk in ICE detention over an op-ed, but similarly against using contempt of Congress to throw Peter Navarro and Steve Bannon in jail, a bullying tactic not used since McCarthy. I was against incarcerating hundreds of J6 protesters based on the same concept now offered by Rubio against visa-holders alleged to be harboring terroristic ideas, intent on a “ruckus.””
“It’s my impression (in part through reporting) that the Trump White House feels itself in a fight for its life and is advertising its willingness to color outside constitutional lines to bring down its targets. That leaves us staring at a protracted battle between two powerful rule-breaking camps, an unprecedented situation and one I haven’t been sure how to think about. Apparently this hesitation is not genuine. Woodhouse and others who’ve raced back into the TDS camp are certain that though I was right to resist media pile-ons before, “that was then, and this is now,” because “if there’s a suffocating, hegemonic political monoculture today, it’s MAGA.””
MAGA is not hegemonic. They have one real TV channel. Just stop. MAGA is preventing NPR and its ilk from being hegemonic. They can’t stand competition or dissenting voices. I think MAGA dissent only occasionally on the right topics—and almost always for the wrong reasons—but allowing the NPR set to stomp out all resistance—as they’ve mostly succeeded in doing with left-wing dissent—is not a good idea. Opinions are like assholes; everyone’s got one, goes the old saying. Maybe it needs an update: even the opinions of assholes are constitutionally protected.
“Trump’s in the White House, but his power base is still mostly all voters, and I’m not sure his people are wrong to think they’ve got maybe a year to smash big law, academia, the media, the DC nomenklatura, the EU, and everything else on their shit list before those entities send the hammer right back. They’re probably also right that if Trump fails, we’ll be back to where we were at the moment of the record scratch seven months ago, staring at a more organized and cynical effort at authoritarianism, with more sophisticated plans for higher “guardrails.””
You Are Already Fully Qualified To Oppose The Genocide In Gaza by Caitlin Johnstone (Substack)
“Obviously you don’t need to go to Gaza to know that the facts and footage you’re seeing coming out of the enclave are awful. No matter how many times you go to Israel and the Palestinian territories, it will still be wrong to bomb hospitals and intentionally starve civilians and create the largest population of child amputees on this planet. But Israel’s apologists are constantly using some version of this tactic to silence Israel’s critics by implying that they don’t have enough personal expertise on this issue to voice opposition to an active genocide.”
 I ain't reading all that; free Palestine
I ain't reading all that; free Palestine
Thoughts On The Israeli Embassy Staff Killings by Caitlin Johnstone (Substack)
“So let’s recap in case anyone’s confused:
“Nothing Israel did to Gaza justified October 7, but also October 7 justifies everything Israel has been doing in Gaza, but also nothing Israel has been doing in Gaza since October 7 justifies any violence toward Israel.
“Everyone got that? Does that sound about right?”
Economy & Finance
Mortgage Your 401(k) by Matt Levine (Bloomberg)
“What percentage of her net worth should a 30-year-old professional have in the stock market? I am not going to give you investment advice, and there is a wide range of plausible answers. “Zero, put it all in Bitcoin” is I guess on the list. A popular rule of thumb would say 70% in stocks, with the other 30% in bonds and cash. There is, however, a good theoretical case that the right answer is really 200%, or 500%: Most of a young professional’s economic wealth is the present value of her future employment income, and borrowing money to buy more stocks is a good way to diversify away from that one risky asset.”
“But it is not easy to put 200% of your net worth into the stock market, because where will you get the money? A mortgage on a house is a pretty standard product in the US, but a mortgage on a retirement account is not.”
“it is psychologically a bit depressing to have most of your retirement contributions go to interest rather than new investments. That is, the problem with borrowing a lot of money to buy stocks for retirement is that it has negative carry: It requires you to pay cash every month, rather than bringing in cash. You are buying stocks for capital appreciation, not steady income, and you have to make years of interest payments to get the payout at the end.”
“What would Satoshi Nakamoto think? What a strange vision of crypto this is. In the future, in every country, you will be able to go to your locally regulated stockbroker and pay a premium of 100% or more to buy shares of stock of a trusted local company, denominated in the local currency, that will hold Bitcoin for you. If you want to transfer your Bitcoin across national borders you can … I don’t know, sell the stock on the exchange through your broker, do a foreign exchange transaction to convert rupees into dirham, find a stockbroker in the target country, open an account, pass know-your-customer checks, fund the account with local currency and then buy stock in that country’s local Bitcoin company (at a 100% or more premium). Seems like it might be easier to buy Bitcoin? But what do I know.”
Is this what “crypto winning” looks like? There is no additional benefit for anyone but the scam artists who got in on this pyramid scheme early. At best, it’s just another speculative vehicle that has been subsumed into the Moloch that the scammers keep pretending they’re trying to replace, when what they’re really trying to do is get into the private boys’ club—getting rich for doing absolutely nothing, just like every other jackass speculative trader and scam artist who ever existed.
“If your baseline assumption is “these trees will get chopped down,” then not chopping down the trees reduces carbon emissions, relative to the baseline of chopping them down. Big companies want to buy carbon credits to offset their own carbon emissions, and not chopping down trees reduces carbon emissions relevant to some baseline, so you can package not-chopping-down-trees into a financial product and sell it for a lot of money to big companies.”
Another scam that people cheerily discuss as if it weren’t a scam. Most people’s scam radars are broken. Or they see them, but they aren’t against scams in principle because they have no principles. They think being a good person is to get on the right side of the deal. Let someone else be a loser who doesn’t have three jet-skis and a giant truck, or a second home in Vail.
“You could imagine reviewing the credits at two levels. There is the level of philosophical legitimacy, where the question is like “is this project that is supposed to be done for the benefit and with the consultation of the local pastoralists actually what they want,” and if the answer is no then you have in a sense bought the carbon credits from people who had no right to sell them. And then there is the level of physical reality, where the questions are like “where are they grazing, how’s the grass doing, and how much carbon is being released,” and if the answer is “everybody’s grazing where they want and the grass is all dead,” then you have bought carbon credits that don’t actually reduce atmospheric carbon.”
Yes. That’s an eloquent description of a scam that I feel most people won’t even reading as a condemnation. Their only concern will be: do I get to pay less taxes? What’s in it for me? Never: is this a good thing to do? The right thing to do? Is my ability to earn without providing value effectively stealing from people who do provide value? The question never crosses their minds. They are entitled. They deserve everything they get because they convince themselves every day that they’ve worked for it, even when they at the same time talk about how much money they’re earning without really having to do much at all (only suckers work).
Elon Musk Needs More Options by Matt Levine (Bloomberg)
“Still it feels like there is a financial product to be built here? You build a huge warehouse at some port in the US, you build a similarly huge floating warehouse on a barge 100 feet offshore, you ship all your products from China to the floating warehouse, they get there, and then you make a tariff call. If you think tariffs will go down next week, you keep them in the offshore warehouse until next week; if you think they’ll go up next week, you move them into the onshore warehouse pronto. (This is extremely not any sort of advice, and I’m sure I’ll get emails saying, like, “no 100 feet offshore doesn’t work.”) And then there’s some rent differential between the two warehouses that serves as an indication of market expectations about the future path of tariffs: The more you think tariffs will go up (down), the more you will pay to stash your stuff onshore (offshore). Build out a whole tariff futures curve from warehouse rents. Anyway this is dumb but the point is that that there is a ton of tariff volatility, and when there is a lot of volatility, there is money to be made as a derivatives structurer. If you can shift your tariff payments in time, you can hedge or speculate on tariff risk. There was not a lot of demand for that a year ago, but now there is.”
“A high percentage return on your small pot of money in your 20s won’t make you much money, but a big percentage loss on your large pot of money in your 60s will cost you a lot of money. By investing a little when you are young and broke, and a lot more when you are at the peak of your career, you end up taking a lot more market risk later than earlier. Your dollar-weighted returns depend largely on how the market does late in your career.”
“Investors use mutual funds to diversify over stocks and over geographies. What is missing is diversification over time. The problem for most investors is that they have too much invested late in their life and not enough early on. … This leads to our simple advice: buy stocks using leverage when young.”
Easier said than done, unless you’re the kind of person who doesn’t have trouble getting leverage, which, definitionally, means that you probably don’t have to worry about your retirement any way you slice it.
“In economics, deadweight loss is the loss of societal economic welfare due to production/consumption of a good at a quantity where marginal benefit (to society) does not equal marginal cost (to society). In other words, there are either goods being produced despite the cost of doing so being larger than the benefit, or additional goods are not being produced despite the fact that the benefits of their production would be larger than the costs. The deadweight loss is the net benefit that is missed out on. While losses to one entity often lead to gains for another, deadweight loss represents the loss that is not regained by anyone else. This loss is therefore[1] attributed to both producers and consumers.
“Deadweight loss can also be a measure of lost economic efficiency when the socially optimal quantity of a good or a service is not produced. Non-optimal production can be caused by monopoly pricing in the case of artificial scarcity, a positive or negative externality, a tax or subsidy, or a binding price ceiling or price floor such as a minimum wage.”
So, where’s the downside exactly? (Reddit)
 I'm already in. You don't have to sell it to me
I'm already in. You don't have to sell it to me
Peter: Tax the fuck out of millionaires.
Harry: A lot of the millionaires would leave the country.
Peter: I’m already in. You don’t have to sell it to me.
Roaming Charges: Sturm und Drang Warnings by Jeffrey St. Clair (CounterPunch)
“According to a new analysis by the Ludwig Institute for Shared Economic Prosperity: “The bottom 60% of U.S. households don’t make enough money to afford a “minimal quality of life.” When you start to refer to the large marjority of your country as “the bottom,” you know you’re in deep, perhaps irreversible economic decline.
“Fortune: “To comfortably afford a typical home, a US household needs to earn about $114,000 a year. That’s a $47,000, or 70.1%, leap compared to 2019. But the real median household income in the United States is only $80,610, per the latest government data.”
“64% of U.S. adults fear financial collapse more than death (the figure is 70% for Gen Xers.)
“Sarah Bundy, who is 54 and still buried under student debt: “Recently, my loan servicer informed me that when my forbearance period ends, my loan payments could be over $2,000 a month. That is more than my monthly take-home pay.””
Environment & Climate Change
The USA is crumbling at the bottom and sinking by Sabine Hossenfelder (YouTube)
“[…] very precise satellite measurements of altitude in twenty-eight of the largest US cities, including Houston, Dallas, New York, and Chicago. They found that at least twenty percent of the urban areas in all of these cities are sinking, mostly due to groundwater extraction. Essentially, the Americans are pumping water out of the ground faster than it can be replaced, and the land is collapsing. In some parts of Houston, they researchers say, the ground is sinking by more than five millimeters a year. That might not sound like much, but over a few decades, it’s enough to crack roads, and damage buildings.”
Art, Literature, & Cinema
Thinking about Soviet films on Victory Day by Evgenia (Nefarious Russians)
“It is interesting that she wasn’t a feminist — that term didn’t exist in USSR — and maybe she didn’t need the concept, because she was a “comrade.” In the USSR women had all equal rights to men since 1917 — which makes America seem so backwards.”
Philosophy, Sociology, & Culture
You control the buttons you press (Reddit)
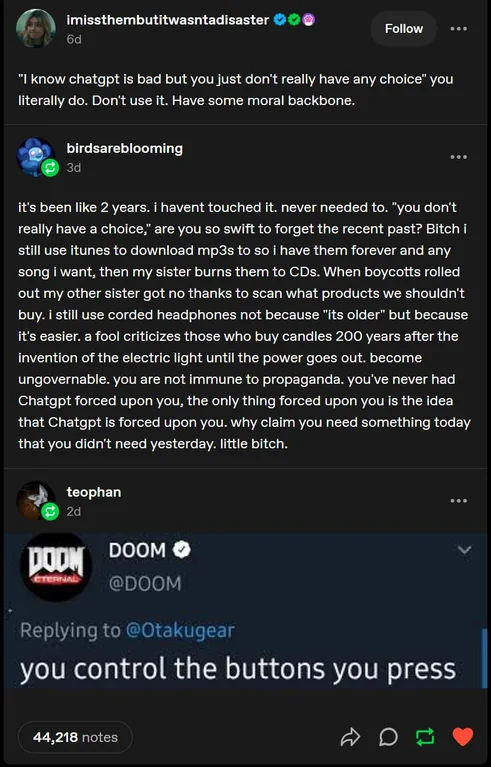 You control the buttons you press
You control the buttons you press
“it’s been like 2 years. I havent touched it. never needed to. “you don’t really have a choice,” are you so swift to forget the recent past? Bitch i still use itunes to download mp3s to so i have them forever and any song i want, then my sister burns them to CDs. When boycotts rolled out my other sister got no thanks to scan what products we shouldn’t buy. i still use corded headphones not because “its older” but because It’s easier. a fool criticizes those who buy candles 200 years after the invention of the electric light until the power goes out. become ungovernable. you are not immune to propaganda. you’ve never had Chatgpt forced upon you, the only thing forced upon you is the idea that Chatgpt is forced upon you. why claim you need something today that you didn’t need yesterday. little bitch.”
✊✊✊
A great comment by Tr41nwr3ckBarbie (Reddit)
“As a therapist, this hit me harder than I expected. Because what you’re describing, beneath all the beautifully chaotic energy, is something I see all the time in practice:
“The belief that “I have no choice”, even when technically, logistically, someone does, is often not laziness or helplessness. It’s a kind of learned powerlessness. It’s what happens when you’ve lived in systems (familial, economic, cultural) that punish resistance, shame slowness, or erase non-conformity.
“So what you’re doing here, saying “you control the buttons you press”, is a reminder of agency, but one that hits with a sharpness most therapeutic spaces would soften. And maybe that sharpness is exactly what people need sometimes. Not for shame, but for reawakening.
“I don’t think the answer is to villainize convenience. But I do think you’re right that we need to challenge this idea that tech, or capitalism, or even therapy-speak somehow overrides the fact that we can choose differently, even if that choice is annoying, slow, unglamorous, or inconvenient.
“Thanks for yelling this. It’s weirdly validating to see someone say out loud what most of us have only muttered under our breath while re-downloading apps we swore we’d quit.”
Doing the work is how you learn. There is no way to get around putting stuff into your head. It’s the only way that you can expect anything useful to ever come out. “Dude, how do you write so much?” “Dude, how could I not?” I read and assimilate so much information that my f&@king cup runneth over the time that I’m not sleeping. And half of my mornings, I get up and stumble to a screen so that I can write down what I woke up thinking. How do you make conversation when all the components of your conversation are a search or a prompt away?
A comment that goes in the same direction by Kevo_1227 (Reddit),
“I have to explain to students all the time that teachers don’t actually need your homework. Like, we don’t have quota on solved math problems or 5 paragraph short essays that has to be met. The point of homework isn’t the finished homework, it’s the process of producing it. We don’t desperately need to know how Republican Rome influenced the Founding Fathers; we need YOU to go through the process of researching, critically analyzing, and reproducing your thoughts in a coherent way. We aren’t worried that people in the future won’t know XYZ factoid or trivia. We’re worried that people in the future won’t know how to learn or think or express themselves with language.”
Technology & Engineering
Top Tier Target | What It Takes to Defend a Cybersecurity Company from Today’s Adversaries by Tom Hegel (Sentinel One)
“Chinese state-sponsored actors targeting organizations aligned with our business and customer base […]”
How can you take cybersecurity companies seriously when they’ve neither seen nor heard of an attack by the U.S.? Their reports are perhaps useful for companies who don’t dare cross the empire but not useful for anyone interested in being secure from the empire, as well.
“That said, more of this activity has been moving to confidential messaging platforms as well (Telegram, Discord, Signal). For example, Telegram bots are used to automate trading this access, and Signal is often used by threat actors to discuss nuance, targeting and initial access operations.”
I can’t help but think that this is how train people to stop trusting apps like Signal—i.e., one of the ones that is not compromised.
PackageId:Microsoft.VisualStudio.Community.Msi;PackageAction:Install;PackageVersion:17.14.36025.13;ReturnCode:1603; (Visual Studio Developer Community)
I ran into a small problem while upgrading Visual Studio 2022 to 17.14.0, so I reported it with the following text,
“The Microsoft.VisualStudio.Community.MSI component could not be installed. At one point, the installer told me that another installer was running, but there wasn’t any installer running. An installer had run before the Visual Studio upgrade: JetBrains Rider. It’s possible that this interfered?
“I am unsure how this problem will affect my work. I don’t really use the MSI tools in Visual Studio (that I’m aware).”
I received a response relatively quickly, as follows:
“After reviewing the error you reported regarding the error with this package PackageId:Microsoft.VisualStudio.Community.Msi;PackageAction:Install;PackageVersion:17.14.36025.13;ReturnCode:1603;.
“Please make sure you have disabled any antivirus, group policies or firewall that you may have on your machine as they sometimes avoid the installations. If they are disables and the error persists, please try the following:
“Step 1: Please go to this path: C:\ProgramData\Microsoft\VisualStudio\Packages
“Step 2: In the above path there should be a folder with the name Microsoft.VisualStudio.Community.Msi;PackageAction. Inside this folder there should be either a .msi or an .exe file, if there is and run it, if there is no .msi or .exe, please delete the folder.
“Step 3: Then go to the VS installer and if there is a “More > Repair” option, select that. If it only shows the option “retry” please select that.
“Step 4: If that workaround was not successful then, try to uninstall Visual Studio using the install cleanup tool
See: https://learn.microsoft.com/en-us/visualstudio/install/uninstall-visual-studio?view=vs-2022#remove-all-with-installcleanupexe. (After you run the command form CMD, please delete the “Installer” folder from the following path and retry the installation: C:\Program Files (x86)\Microsoft Visual Studio)“Please let me know if the solution worked for you! If not, we will continue investigating your issue.
“Let us know if there’s anything else I can help you with.”
I replied as follows:
Thanks for you help. I’ve found the folder you described and run the installer.
I also found the More => Repair option but elected not to execute it because it warns me that,
“Repairing will reset the environment. Local customizations like per-user extensions and your user settings will be removed. Your synchronized settings will be restored.”
I’m not so interested in getting rid of that ⚠️ icon in the VS installer that I’m going to take the time to re-install all of my extensions. I’ll just wait for the next VS update to (hopefully) clean things up for me.
For the same reason, I’m not going to reinstall VS unless something I actually use has stopped working.
On a final note, I was somewhat surprised to see this advice:
“Please make sure you have disabled any antivirus, group policies or firewall that you may have on your machine as they sometimes avoid the installations.”
While I understand that Windows Defender can issue false positives, I’m not a fan of the advice “don’t worry bro, our installer will work just fine once you disable all of the security on your machine.” I mean, that sounds like something an actual scammer would say. No offense.
On top of that, there are a lot of users (myself included) who work on machines configured by other organizations who do not have control over antivirus or firewall on our machines. I don’t know what you mean by “disable group policies” because they are legion and cannot “all” be disabled.
Thanks again for the detailed instructions. They worked as advertised. If I run into more problems, then I’ll have to try the “Repair” option.
Mozilla is killing its Pocket and Fakespot services to focus on Firefox by Kevin Purdy (Ars Technica)
“Pocket started in 2007 as Read It Later, a way to bookmark web articles for later reading. It’s not just the focus on published text articles that now seems quaint but also the idea that there was a finite amount of web material you would get back to and would have the time to do so. Those who do want that nice-sounding media experience can cobble it together in most modern browsers, which have built-in tools for managing bookmarks, distinct “reading lists,” and even creating stripped-down “readable” versions of articles.”
Authors like this don’t even seem to want to pretend to lament that we’re living in a world where people (A) don’t read and (B) don’t curate their own content. Even the thought of doing something like that is described as if it were ludicrous, an antiquated habit. “Hey, lookit grandpa over there, reading articles of his own choosing. What a loser..”
Well, grandpa is flexing muscles you can only dream of and growing wiser and more knowledgeable while you’re chugging down one 23-second video after another about shit you couldn’t truly care less about except that it delivers an ever-dwindling dopamine hit to your ever-smoothening brain. Hey, lookit grandpa, chaining words together into sentences that make you feel bad about yourself.
LLMs & AI
To Write Well With AI, Write Against It by Kyle Munkittrick (3QuarksDaily)
“The sycophantic critic is an under-appreciated, and, to me, equally concerning, risk of using AI when writing. Yes, using AI to write for you will erode your thinking and creativity, but so too, possibly, can writing for the AI. Sycophancy is a tempting behavior of AI. My AI critic told me what I wanted to hear about my writing rather than the truth about it.”
A Critical Look at MCP by Rasmus Holm (Raz Blog)
“Am I being pretentious/judgmental in thinking that people in AI only really know Python, and the “well, it works on my computer” approach is still considered acceptable? This should be glaringly obvious to anyone that ever tried to run anything from Hugging Face.
“If you want to run MCP locally, wouldn’t you prefer a portable language like Rust, Go, or even VM-based options such as Java or C#?”
I’ve been having discussions with people at work about MCP. This post made me think that I haven’t been clear about my attitude toward it. I think it would be amazing if we could pose natural language queries to machines and have them do things for us. Absolutely. “Tea. Earl grey. Hot.”.
My doubts are more specific to MCP itself, technically, as a protocol. This article is highly technical, but it boils down to: MCP is such a hype-y protocol right now and it’s so technically shaky that we have a responsibility to not just grab the first damned thing that shows up and make it the standard. We did that with JavaScript and it took 2 years until it was everywhere and over 20 years until it was an actual professional tool. I’m an old man and, looking back, very often our industry is just stepping on rakes that are right there.
I just to clarify that I’m pushing back on the implementation not the idea.
They Cheated Themselves…But Don’t Realize Why: Eternally In Search of the Thinker’s High by Steven Gimbel (3QuarksDaily)
“The point of the question was not to write down the correct answer. Rather, the value of the exercise was to wrestle with something that seems at first glance trivially easy, but then gets hard when you consider boundary cases. Take this straightforward case and see how tricky it is in order to start building the cognitive muscles you’ll need when thinking about justice, God, truth, or love. It is the process, the struggle, that is important. And that is precisely what our contemporary AI eliminates.
“I asked how many work-out and most hands went up. I then asked if they could lift more with a forklift. When they said yes, I asked “Then, why not take one to the gym?” This turned into a utilitarian justification of building skills that will benefit them in their future.”
Remarks on AI from NZ by Neal Stephenson (Substack)
“Speaking of the effects of technology on individuals and society as a whole, Marshall McLuhan wrote that every augmentation is also an amputation. I first heard that quote twenty years ago from a computer scientist at Stanford who was addressing a room full of colleagues—all highly educated, technically proficient, motivated experts who well understood the import of McLuhan’s warning and who probably thought about it often, as I have done, whenever they subsequently adopted some new labor-saving technology. Today, quite suddenly, billions of people have access to AI systems that provide augmentations, and inflict amputations, far more substantial than anything McLuhan could have imagined. This is the main thing I worry about currently as far as AI is concerned. I follow conversations among professional educators who all report the same phenomenon, which is that their students use ChatGPT for everything, and in consequence learn nothing. We may end up with at least one generation of people who are like the Eloi in H.G. Wells’s The Time Machine, in that they are mental weaklings utterly dependent on technologies that they don’t understand and that they could never rebuild from scratch were they to break down.”
This has already largely happened. We have an entire generation seriously affected by having grown up positively enmired in social media, where fleeting and wholly uninformed opinions replaced reading books, where media’s capitulation to power was nearly complete, where information was much more intensely managed and controlled for the majority. The intense propaganda has always been there but it’s power and capacity for control has increased incredibly. Now, we have a generation that not only suffers under this information regime but now also that of LLMs and so-called AI.
No-one knows anything anymore.
OK. That’s not true. But the number of people who know useful things are basically a rounding error compared to people that sleepwalk through life, no different in principle than the human batteries from the Matrix except that they’re not trapped in giant towers.
There are a relative handful of people who have the capacity and context to understand how the more important parts of the world works, but most people are utterly helpless to understand anything at level of depth that isn’t an embarrassment to them.
How does anything in cars or satellites or cell phones or computers or data centers or the cloud or apps work? No idea. How do light bulbs work? How do circuits work? Why do they work? How does the power grid work? What’s even possible there? How does basic morality or ethics work? No idea. No idea. No idea. How are clothes produced? How does international shipping work? Why do planes fly? How do get building materials? Where do they even come from? How do people stay alive? How do you convert food into energy? No idea. No idea.
Who hates AI and why? by Iris Meredith (Dead Simple Tech)
Despite the provocative title, I think that the distinction this article makes between transformative and compositional work is an important one. It provides a more solid, theoretical structure for reasoning about why LLMs seem to be more appropriate to some tasks where they are actively harmful for others.
We’ve discussed vaguely that they’re good for “greenfield” or “POCs” but tend to be bad at “following rules”. This is explained in this article as some tasks being highly compositional in nature, in which pros and cons of components are evaluated against an existing context (team, skills, money, etc.)
Even in so-called transformational work, you are very quickly, as a programmer, involved in compositional rather than transformational work. As soon as you’re integrating new code into an existing solution, you’re bringing a lot of implicit context and knowledge to how you choose a solution that you will have to make explicit in order for an LLM to even begin to guess an appropriate solution.
“While work is obviously a very, very complicated thing, a useful lens for the purpose of this essay is to draw a distinction between work which reshapes a raw material into a finished object and work that puts together multiple objects in a way that creates a certain effect in the world. For the sake of having a shorthand, I’ve chosen to call them transformative and compositional work, respectively.”
“[…] the job of an application developer is to build an app that will naturally do something, using the programming language as the raw material being used. How that app works with other pieces of software (or even the deployment infrastructure) is a secondary consideration to the internal function of the application and the question of whether it does what we want it to do.”
“DevOps and infrastructure are, on the whole, highly compositional fields: the goal isn’t usually to create de novo entities unless you really need them to fit into an existing process or system, and instead you’re usually using black box components (CI/CD tools, Docker containers, OpenTofu resources) together in order to achieve some kind of effect. Containerisation technologies really bring this into sharp relief: it’s no surprise that one of the more popular simple orchestration tools out there is called Compose, and the entire ethos of containerisation + immutable infrastructure is very much a compositional one.”
“And it’s this observation, I think, that goes some way to explaining the observed trend in LLM scepticism. All of the fields I’ve mentioned above tend to take a compositional stance, whereas boosters tend to work in fields (like the aforementioned app development) where the common stance is far more transformative.”
“[…] the only constraint you can apply to LLM output is, fundamentally, the prompt. This might be OK for creating a standalone artifact, but when doing compositional work, satisfying competing constraints while achieving a goal is the core of the task. You need to be able to make tools interact with previously specified interfaces, meet robustness and security guarantees and half a hundred other things that you simply can’t get from other prompts. For that matter, an LLM can’t even maintain meaningful consistency from prompt to prompt, so even if you manage to produce (somehow) one useful object using an LLM, there’s approximately zero hope that any other objects you generate with an LLM being consistent with the first one.”
“Choice is no better. An LLM is ignorant of the context and implicit knowledge that a practitioner has and knows nothing of the goals or design of the system you’re trying to build. While it might have a slight advantage over a practitioner in terms of discovery (LLMs can throw up tools that you might not otherwise have known existed), it can of course also hallucinate stuff about the things you’re trying to make a choice about that just aren’t true, and simply has no grounds on which to inform a decision as to which tool to use. Furthermore, LLMs are a statistical average of human language, and are thus highly likely to give you an average solution. Given how bad the average solution is, average is not good enough: it leads to things like suggesting the use of React for a basic static site or Kubernetes for one dockerised application. A compositional practitioner of any real quality is quickly going to find this annoying.”
“This, to my mind, underlies a lot of the core conflict between (sensible) sceptics and (sensible) advocates: we’re trying to do very different things in a field where the differences have been obscured by the halo of “tech”. A transformative practitioner sees the technology as something good for proofs-of-concept, exploring vague thoughts and trying to build towards something new (many of them will eventually get frustrated with it, of course). Even with its flaws and the things it does badly, it can still feel like one’s making progress. A compositional practitioner, by contrast, finds the thing immensely irritating almost immediately. The LLM comes across primarily as an electronic dumbass that’s constantly wrong about everything, the mistakes it makes are unforgivable in a field where slight mistakes can mean frequent outages, security breaches and massive cloud bills, and it is worse than useless in the core skill of making the choices of which parts to include in your project. The LLM therefore becomes immensely more of a nuisance to a compositional practitioner than to a transformative one.”
“This is particularly glaring in the case of Silicon Valley and the Venture Capital industry more generally. What’s lauded as innovation is almost exclusively the new thing rather than old things put together in new ways: the sword rather than the machined rifle. Mark Zuckerberg created a website that let Harvard students rate each other on fuckability (to use Cory Doctorow’s excellent phrase): the many, many engineers that built and developed the infrastructure to let that website scale and work reliably is never mentioned.”
“Compositional innovation, for all that it’s not as exciting as the transformative kind, also seems to do better for most people on the whole. I care a whole lot more about sewage systems and electricity than I do about Facebook, and even in the space of computers, I’m much more of a believer in boring things that let people be interesting than new, exciting and interesting technologies that make people boring and shallow. LLMs, serving only the transformative kind of innovation, and that mostly badly and wastefully, are thus something that I’m naturally going to despise.
“When the LLM hype inevitably ends, and perhaps even a little before then, we need to remember that, unfashionable though it might be, compositional work is just as important as the transformative kind and it needs to be respected and valued. This means respecting and valuing the attitudes and ways of being of the people who do it, and rather than constantly trying to force a very limited version of innovation on us, let us do things the way we like to achieve the ends we want.”
Claude and I write a utility program by Mark Dominus (Universe of Everything)
“On the whole it went extremely well. The complete transcript is here. I imagine this was pretty much a maximally good experience, that all the terrible problems of LLM coding arise in larger, more complicated systems. But this program is small and self-contained, with no subtleties, so the LLM could be at its best.
“[…]
“The program it wrote it was not what I would have written, but it was good enough. If I had just used it right off the bat, instead of writing my own, it would have been enough, and it would have taken somewhere between 2% and 10% as long to produce.
“So the one-line summary of this article is: I should stop writing simple command-line utilities, and just have Claude write them instead, because Claude’s are good enough, and definitely better than yak-shaving.”
“I just said to Claude:”“This is good, now please add code at the top to handle argument parsing with the standardArgparselibrary, even though there are no options yet.”“Claude handed me back pretty much the same program, but with the argument parser at the top.
“Let’s pause for a moment. Maybe you kids are unimpressed by this. But if someone had sent this interaction back in time and showed it to me even as late as five years ago, I would have been stunned. It would have been completely science-fictional. The code that it produced is not so impressive, maybe, but that I was able to get it in response to an unstructured request in plain English is like seeing a nuclear-powered jetpack in action.”
“Partway along I was writing a test script and I wanted to use that Bash flag that tells Bash to quit early if any of the subcommands fails. I can never remember what that flag is called. Normally I would have hunted for it in one of my own shell scripts, or groveled over the 378 options in the bash manual. This time I just asked in plain English “What’s the bash option that tells the script to abort if a command fails?” Claude told me, and we went back to what we were doing.”
And here Mark corroborates something I’ve thought a few times now: that the LLM’s ability to only help well with cleanly written, modular code and requirements … might lead people to finally start writing requirements and modular code.
“Programmers often write closely-coupled modules knowing that it is bad and it will cause maintenance headaches down the line, knowing that the problems will most likely be someone else’s to deal with. But what if writing closely-coupled modules had an immediate cost today, the cost being that the LLM would be less helpful and more likely to mess up today’s code? Maybe programmers would be more careful about letting that happen!”
Of course, only if they’re capable of doing that. Which the LLM won’t teach them.
'Forbidden' AI Technique − Computerphile by Computerphile / Chana Messinger (YouTube)
This ~10-minute video discusses research about chain-of-thought LLMs that “show their work”. Chana points out that, once you can see what the machine says its doing, it’s actually openly discussing “cheating” to achieve the correct result. She says that, once you add penalties for “cheating”, the machine doesn’t stop cheating—it simply stops writing about it. While this feels hilarious because it really seems to be acting like a teenager, it’s exactly this kind of anthropomorphizing that is both so seductive and potentially counterproductive.
Anthropic published a long paper recently called Circuit Tracing: Revealing Computational Graphs in Language Models in which they note that their research shows that the explanation offered by an LLM for how it arrived at an answer does not always—or even often—correspond to the actual path that the solution-generation took through the model’s layers, when examined in detail.
Even though Chana says that the LLM is describing how it’s going to “cheat” at getting to the answer that it knows has the greatest “weight”—i.e., it’s the thing that the questioner very clearly wants to hear, or gets statistically closest to the “answer” that was given in the eval included in the query—it’s actually describing this in a part of its processing that is only associated with generating the chain of thought and has little to nothing to do with producing the actual answer itself.
What we consider to be the “chain of thought” is just more text being generated to the LLM. It’s just as likely to be completely made-up and has little to nothing to do with the construction of the answer itself. The LLM doesn’t “know” that it’s explaining one part of a text with another, just like it doesn’t “know” that it’s “lying” or “cheating”.
The LLM is generating an answer that best satisfies the weights in its model (generated during training), combined with the “pressures” included in the system prompt and the query. It’s the human interlocutor who imbues the situation with humanity or intent, not the machine. The context is that you’re “talking to something” and the interpretive gloss is wholly one-sided. The other side is just cheerily crunching numbers.
I’m not convinced by Chana’s explanation that the LLM is actually “hiding private messages to itself” with steganography because the better explanation comes from the Anthropic paper linked above, not the OpenAI one she discusses. However, I think that it’s definitely good advice to avoid these types of validation pressures, not because the models are “trying to trick us, or hack us” but that they don’t lead to the desired result.
I think this research is fascinating because, even though there is no-one on the other side (or it’s one of Searle’s Chinese Rooms), we still might be able to figure out how to manipulate the machine to give us what we want reliably. While I understand that the anthropomorphizing explanation is more approachable, I’m leery of the limiting effect it has on how we think about solutions.
Who’s Coding Now? AI and the Future of Software Development by AI + a16z (Apple Podcasts)
This podcast episode was recommended to me by a colleague.
“There was a good blog debate about whether we’re overinvested in AI. I think the number was $200B annual investment. And I think the question was how we would recuperate it?
“Well, here we have a way to recuperate $3T, which makes the $200B look like peanuts.”
Sure, sure … except that people have to invest $200B first and the guy is saying that a $3T market will appear. There is no evidence for that market yet but everybody’s saying that there is. This is called an echo chamber (Wikipedia) and it’s the perfect place to brew up market bubbles. The nice thing for them is that, even if the $3T never shows up, they’ll still have gotten the $200B.
A little bit later, they’re discussing how they use the tools but they don’t talk about which problems they’re solving. One person said that they start with specs, which is great. The others talk about how “no-one can remember all of the CSS classes like margin or padding…”, which makes my eye twitch. It’s like hearing your car mechanic say, right before they’re leaning in to fix your car, “no-one knows what all these wires are for…”
The host sounds like it’s an AI reading pre-canned text. I don’t think that it’s a person in the conversation. It basically throws up straw-man, leading questions, like
“Is there some way to get the neckbeards engaged?”
Ah, yes, if people don’t jump on board with your scam—or they threaten to try to dissuade people from getting suckered themselves—then disparage those critics as nerds, training your minions to be unquestioning monkeys who don’t want to be called names. Don’t you want to be a cool-kid, AI-tool user making tons of money? Or would you rather be a neckbeard/hater/loser who’s going to lose his job to the cool kids?
If it’s such an obviously good thing, then why do you have to try so hard to sell it? Is it because you’re selling a solution to a problem that people don’t know they have? Is the problem that they don’t have a problem that your tool can solve? Or that they don’t recognize they that have a problem? Why can’t the tool’s performance speak for itself? Why does it need so much hype?
“Given enough context and given enough tools…”
The problem, as far as this lady is concerned, is that people aren’t able to use the tools enough yet, otherwise they’d be even better at helping you! And maybe you need to spend $200/month to get it working…and if it still doesn’t work, then it’s your fault.
They very lightly discuss context-poisoning and how the models will cheerfully offer wrong answers rather than admit when they don’t know something. They don’t offer any advice about what to do about it (e.g., resetting context in order to resolve poisoning, but that’s a “nuke it from orbit” solution that may throw out the baby with the bathwater). One of the guys says that LLMs are really good at more-complex tasks, which I think he misspoke, but I can’t be sure.
They admit that “models are not really creative…” and then say that if you’re doing something new, then it won’t help at all. I think that’s actually wrong! They can still be used as code-completion, even if it would be useless to try to have the LLM design the whole thing (which kind of works for tasks that have been done a million times before).
One problem I have with these kinds of podcasts is that they sometimes feel so outside of history and prior work. The people seem to be considering problems of how we learn, how we create, and other questions of philosophy for the first time, which makes their analysis pretty superficial—because they’re retreading territory that many others have already covered, sometimes for centuries, if not millennia. I find myself thinking, yeah, that’s Kant, yup, there’s Hobbes; oooh, there’s Confuscius!
I love how Yoko Li says “I talked to a classic vibe-coder the other day…” when the term vibe-coding was introduced just 3.5 months ago. In this world, one quarter is old and classic. Remember that that’s their context. Next up, she talks about the same Blender MCP example that I’d already heard about from one colleague and in a video that another colleague had sent to me.
“A temperature-zero model is technically deterministic. The problem is that a miniscule change in the context will introduce a change in the output. … it’s chaotic…”
For the end-user, it doesn’t really matter why the result seems chaotic, it just is. This observation is more of interest to those building tools on top of these LLMs, as it might give a hint as to how to improve reproducibility, which is paramount to establishing these tools as part of more workflows.
TIL I learned the term narrow waist, which is a concept, interface, or protocol that solves an interoperability problem (e.g., file-encodings, POSIX, IP, JSON, HTTP), which allow software to address N variations on a problem with a single solution. They discuss whether the “prompt language” might be such a narrow waist. I don’t think we’re anywhere close to deciding that. It is much too vaguely defined and it’s utterly unclear whether the current paradigm will even survive.
Remember, everyone: OpenAI is simultaneously the most successful AI company and the most unprofitable company of any kind in history. Don’t get too comfy using a tool that no-one has figured out how to provide in anything approaching an economically feasible way.
Overall, it was a much better discussion than I’d expected when I saw that it was an A16Z podcast. They weren’t very clear on which companies and which business models would benefit from writing software in this way, or when they should jump on board, and with which tools. The implication is, as usual, everybody should be using all the things, and they should have started yesterday.
Their context seems to be that, if you haven’t figured out how to profit from using AI, then it’s not a problem with the technology, but because you’re not trying hard enough. A more balanced take would at least leave open the possibility that some businesses might not need AI, or at least that there’s no business case for using the current iterations of it.
Businesses really have to consider what level of investment—in training and monthly licenses—makes sense for them. A16Z benefits from a world that considers the services they’re investing in to be essential to every facet of life.
New Claude 4 AI model refactored code for 7 hours straight by Benj Edwards (Ars Technica)
This article talks about how awesome Claude is but then when you look at all of the charts, you see that it’s data published by Anthropic about its software, publishing impressive percentages indicating some performance in benchmarks that they made up. So, they’re telling you that their software is amazing according to measures that you only learned about from them.
But they wouldn’t lie to get more investor money, would they? They wouldn’t just make shit up in order to get more people to invest in their deeply struggling if not outright failing and functionally bankrupt companies, would they?
Doesn’t anyone else remember Elizabeth Holmes? Theranos? Her company was worth $9B at one point. She had a plastic box that didn’t do anything. She got people to donate billions to her cause. No-one wanted to miss out on this amazing speculative venture. Did they believe her? Maybe some did. Maybe most did. But probably more than enough were just playing the “greater fool” gamble, speculating that they could buy in early and get out the bubble collapsed.
So don’t tell me that there is no way that dozens of billions of dollars could be spilled on something that doesn’t anything close to what it does on the tin. Scams like that are the foundational girders of our modern economy. They are not there to do the thing that they say on the tin—the description is marketing to draw in suckers, while the real investors get in early and jump out before the soufflé pops, leaving a lot of naifs holding the bag.
Their boldness is impressive, though. They’re even flat-out telling you that you have to pay a lot of money to buy a service that’s shaky to use, at best.
““I empathize with a lot of people out there trying to use our APIs and language models generally because they have to almost shift their perspective on what it means for reliability, what it means for powering a core of your application in a non-deterministic way,” Albert added. “These are general oddities that have kind of just been flipped, and it definitely makes things more difficult, but I think it opens up a lot of possibilities as well.””
They “empathize” with your inability to draw consistent value from their service. That’s just the nature of it. It’s absolutely gorgeous Hochstaplerei: go big or go home. The more you charge, the more people will want it. You can even admit instabilities because they look like you’re fucking Doc Ock trying to control the power of the atom with his robot arms. Who could blame you if the product is a bit rough around the edges when you’re harnessing the power of the stars for your customers? We are on the edge of greatness here. Can you afford to miss out?
I really don’t like ChatGPT’s new memory dossier by Simon Willison
“I’m an LLM power-user. I’ve spent a couple of years now figuring out the best way to prompt these systems to give them exactly what I want.
“The entire game when it comes to prompting LLMs is to carefully control their context—the inputs (and subsequent outputs) that make it into the current conversation with the model.
“The previous memory feature—where the model would sometimes take notes on things I’d told it—still kept me in control. I could browse those notes at any time to see exactly what was being recorded, and delete the ones that weren’t helpful for my ongoing prompts.
“The new memory feature removes that control completely.
“I try a lot of stupid things with these models. I really don’t want my fondness for dogs wearing pelican costumes to affect my future prompts where I’m trying to get actual work done!”
He describes a quick analysis of how the feature seems to work.
“[…] it looks like this is yet another system prompt hack. ChatGPT effectively maintains a detailed summary of your previous conversations, updating it frequently with new details. The summary then gets injected into the context every time you start a new chat.”
In the example from the article, the image he’d generated included a giant sign that included text from a previous chat. In this case, it was immediately obvious that the LLM was using something other than the image, the prompt, the current conversation context, and the system prompt to generate the image.
But what if it’s not that obvious? Are we going to notice a subtle detail that reveals something really private or secret? Take a look at the initial image he submitted and the final generated image, which purports to be a copy of the original with the details from the prompt added to it. If you compare those two images, you’ll see that, though the main elements look the same, there are enough subtle differences to show that all of the elements have been regenerated, not “copied”.
We’re seduced into thinking that they’ve been copied. It never has been. This regeneration had classically been influenced by the system prompt and conversation context. Now, it’s also being influenced by “memory” of other conversations. It’s going to be impossible to know which past details influenced the generation of that background—or what they might reveal about other conversations. In a sense, this is just repeating the “Google Search Bubble” but in an even more obscured way.
The second half of the post describes not only how you can disable the feature (for now) but also prompts to (supposedly) cajole the contents of your conversational context out of the LLM. Willison doesn’t seem to consider how much confabulation/hallucination affects that response.
Whether it’s “true” or not, the result is a large amount of detailed information that the chatbot collects and synthesizes. Taken together with most people’s tendency/compulsion to just believe anything that they read, especially if it seems to have been formulated in a science-y or intelligent-sounding way, we can look forward to a future where OpenAI’s business model is selling these profiles to your employer, health-insurance companies, and the tax authorities—and them then acting on these data ruthlessly and unquestioningly.
Initially, I thought Willison might be overreacting but now, after a bit of consideration, I’m more convinced that this feature—although it purports to be helpful—is actually quite hostile to the user’s ability to retain control over the tool—and not vice versa.
It’s time to have a concept like a web browser’s “private tabs” to keep things separate. Of course, this won’t protect most users as it’s easy to forget what’s going on the background with all of these tools. Most of our apps are designed to comfort us into following their pattern, not letting us tell them how we’d like to work.
At the very end, Willison offers hope for an actual user-empowering feature: including conversational context for projects, where you’ve tightly defined which conversations can be used for context where. I’m not sure how useful this would be, though. Some of the main advice for fixing context-poisoning that leads to pathologically unusable answers is to “throw everything away”. If that’s still the go-to answer for “fixing” a broken conversation, it seems very counterproductive and disempowering to have context included that you can’t remove.
Programming
Scaling HNSW in RavenDB: Optimizing for inadequate hardware by Oren Eini (Ayende)
“Distance computation is doing math on two 3KB vectors, and on a large graph (tens of millions), you’ll typically need to run between 500 − 1,500 distance comparisons. To give some context, adding an item to a B+Tree of the same size will have fewer than twenty comparisons (and highly localized ones, at that). That means reading about 2MB of data per insert on average. Even if everything is in memory, you are going to be paying a significant cost here in CPU cycles. If the data does not reside in memory, you have to fetch it (and it isn’t as neat as having a single 2MB range to read, it is scattered all over the place, and you need to traverse the graph in order to find what you need to read).”
I just saw a neat code example from a Dutch government project (function starting at line 182), reproduced below.
private static string GetPercentageRounds(double percentage)
{
if (percentage == 0)
return "⚪⚪⚪⚪⚪⚪⚪⚪⚪⚪";
if (percentage > 0.0 && percentage <= 0.1)
return "🔵⚪⚪⚪⚪⚪⚪⚪⚪⚪";
if (percentage > 0.1 && percentage <= 0.2)
return "🔵🔵⚪⚪⚪⚪⚪⚪⚪⚪";
if (percentage > 0.2 && percentage <= 0.3)
return "🔵🔵🔵⚪⚪⚪⚪⚪⚪⚪";
if (percentage > 0.3 && percentage <= 0.4)
return "🔵🔵🔵🔵⚪⚪⚪⚪⚪⚪";
if (percentage > 0.4 && percentage <= 0.5)
return "🔵🔵🔵🔵🔵⚪⚪⚪⚪⚪";
if (percentage > 0.5 && percentage <= 0.6)
return "🔵🔵🔵🔵🔵🔵⚪⚪⚪⚪";
if (percentage > 0.6 && percentage <= 0.7)
return "🔵🔵🔵🔵🔵🔵🔵⚪⚪⚪";
if (percentage > 0.7 && percentage <= 0.8)
return "🔵🔵🔵🔵🔵🔵🔵🔵⚪⚪";
if (percentage > 0.8 && percentage <= 0.9)
return "🔵🔵🔵🔵🔵🔵🔵🔵🔵⚪";
return "🔵🔵🔵🔵🔵🔵🔵🔵🔵🔵";
}The commentator at Reddit wrote,
“Some people laughed at it and suggested all kind of clever one liners to replace it, but to me, that if statement is perfect. The intent is immediately clear and bugs are easy to spot. This is the kind of code you want in critical apps.”
This is a cool example because it demonstrates how easy it is to understand the return value when you don’t use a constant for the “progress bar” symbol and when you don’t use something like new string(“🔵”, 5).
Still, all but the first condition needlessly checks the lower-bound already guaranteed by the previous step. At the very least, you could reduce it to the following:
private static string GetPercentageRounds(double percentage)
{
if (percentage == 0)
return "⚪⚪⚪⚪⚪⚪⚪⚪⚪⚪";
if (percentage <= 0.1)
return "🔵⚪⚪⚪⚪⚪⚪⚪⚪⚪";
if (percentage <= 0.2)
return "🔵🔵⚪⚪⚪⚪⚪⚪⚪⚪";
if (percentage <= 0.3)
return "🔵🔵🔵⚪⚪⚪⚪⚪⚪⚪";
if (percentage <= 0.4)
return "🔵🔵🔵🔵⚪⚪⚪⚪⚪⚪";
if (percentage <= 0.5)
return "🔵🔵🔵🔵🔵⚪⚪⚪⚪⚪";
if (percentage <= 0.6)
return "🔵🔵🔵🔵🔵🔵⚪⚪⚪⚪";
if (percentage <= 0.7)
return "🔵🔵🔵🔵🔵🔵🔵⚪⚪⚪";
if (percentage <= 0.8)
return "🔵🔵🔵🔵🔵🔵🔵🔵⚪⚪";
if (percentage <= 0.9)
return "🔵🔵🔵🔵🔵🔵🔵🔵🔵⚪";
return "🔵🔵🔵🔵🔵🔵🔵🔵🔵🔵";
}I would elect to go further, preserving the clarity in constants (or maybe a comment) to avoid repetition in the code.
First, let’s write a test with NUnit.
[TestCase(0.00, "⚪⚪⚪⚪⚪⚪⚪⚪⚪⚪")]
[TestCase(0.10, "🔵⚪⚪⚪⚪⚪⚪⚪⚪⚪")]
[TestCase(0.11, "🔵⚪⚪⚪⚪⚪⚪⚪⚪⚪")]
[TestCase(0.19, "🔵⚪⚪⚪⚪⚪⚪⚪⚪⚪")]
[TestCase(0.20, "🔵🔵⚪⚪⚪⚪⚪⚪⚪⚪")]
[TestCase(0.30, "🔵🔵🔵⚪⚪⚪⚪⚪⚪⚪")]
[TestCase(0.40, "🔵🔵🔵🔵⚪⚪⚪⚪⚪⚪")]
[TestCase(0.50, "🔵🔵🔵🔵🔵⚪⚪⚪⚪⚪")]
[TestCase(0.60, "🔵🔵🔵🔵🔵🔵⚪⚪⚪⚪")]
[TestCase(0.70, "🔵🔵🔵🔵🔵🔵🔵⚪⚪⚪")]
[TestCase(0.80, "🔵🔵🔵🔵🔵🔵🔵🔵⚪⚪")]
[TestCase(0.90, "🔵🔵🔵🔵🔵🔵🔵🔵🔵⚪")]
[TestCase(1.00, "🔵🔵🔵🔵🔵🔵🔵🔵🔵🔵")]
public void TestBubbles(double percentage, string expectedOutput)
{
var actualOutput = GetPercentageRounds(percentage);
Assert.That(actualOutput, Is.EqualTo(expectedOutput));
}Next, let’s give in to our refactoring instincts and see if a shorter formulation of the algorithm is also understandable. The algorithm is now:
- Build constant buffers for
zeroandall. - Calculate the portion of each of these buffers to include in the result (
filledCountandemptyCount). - Copy the correct number of characters from the buffers using the C# range-operator.
private static string GetPercentageRounds(double percentage)
{
const string empty = "⚪⚪⚪⚪⚪⚪⚪⚪⚪⚪";
const string filled = "🔵🔵🔵🔵🔵🔵🔵🔵🔵🔵";
var filledCount = (int)Math.Floor(percentage * 10);
var emptyCount = 10 − filledCount;
return filled[..filledCount] + empty[..emptyCount];
}This doesn’t work, though!
The tests fail. For example, the test for 0.8 returns “🔵🔵🔵🔵⚪⚪” instead of “🔵🔵🔵🔵🔵🔵🔵🔵⚪⚪”. What’s going on?
There’s another hint as to what is going on if we were to refactor the constant declarations to use each symbol only once. I could create the string with a special constructor instead, as shown below.
var empty = new string ('⚪', 10);
var filled = new string ('🔵', 10);This avoids repeating the symbol several times but it’s probably also not as clear what’s happening. It also no longer uses constants—initialized once and stored in the app—so we’re allocating new strings each time. We could declare them as static instance variables so that they are allocated only once. However, we can’t declare them locally in the method, which again decreases readability.
On top of that, though, the second initialization doesn’t even compile!
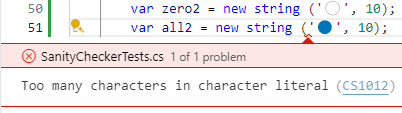 🔵 is not a single character
🔵 is not a single character
Strings are encoded in UTF-16 (the standard for .NET). In this encoding, the “⚪” is represented with one byte, while “🔵” is represented with two bytes. That knowledge, together with knowing that the range operator works with bytes, explains why we only got half as many filled-in symbols as expected.
Knowing this, we can revert to the original constants and fix the algorithm as follows (code-change is highlighted).
private static string GetPercentageRounds(double percentage)
{
const string empty = "⚪⚪⚪⚪⚪⚪⚪⚪⚪⚪";
const string filled = "🔵🔵🔵🔵🔵🔵🔵🔵🔵🔵";
var filledCount = (int)Math.Floor(percentage * 10);
var emptyCount = 10 − filledCount;
return filled[..(2 * filledCount)] + empty[..emptyCount];
}OK. Now it’s working. We now have two questions:
- Can we avoid the “hack” for UTF-16 in our calculation?
- The code is now more maintainable; is the code still as understandable as before?
Let’s tackle the first one. It turns out that there is a standard way of indexing by grapheme but you have to opt in to it by using a StringInfo object, which offers a method named SubstringByTextElements().
private static string GetPercentageRounds(double percentage)
{
const string empty = "⚪⚪⚪⚪⚪⚪⚪⚪⚪⚪";
const string filled = "🔵🔵🔵🔵🔵🔵🔵🔵🔵🔵";
var filledCount = (int)Math.Floor(percentage * 10);
var emptyCount = 10 − filledCount;
return new StringInfo(filled).SubstringByTextElements(0, filledCount) + new StringInfo(empty).SubstringByTextElements(0, emptyCount);
}Now our code is no longer making assumptions about how many bytes represent our empty and filled symbols. But is it better? No. It is absolutely less legible than even the previous version.
Is it even necessary? Also no.
Why wouldn’t it be necessary? In the general case, we have to stay flexible and make sure that we’re extracting the correct number of graphemes (not characters), but we don’t have a general case here. We have two constant strings in a known encoding. We know that we can index by byte into the empty string and we know that we can index by two bytes into the filled string. These are constants. They will not change. We can make assumptions based on that.
That means, after this little excursion, that we’ll return to our original version but we will also no longer consider it a hack.
This takes us to the final point: is the new version more legible than the original? I think that it is. At first blush, the original looks like it’s very self-explanatory—you can see how the progress bar is built—but you also have many more points of logic to check to verify that it’s actually working as expected. While you can use the test I’ve defined above to check all of the logic, there are many more conditions to check when something goes wrong. We measure the number of paths through a piece of logic as cyclomatic complexity (Wikipedia). The lower the better.
We have learned that, when you program in the original way, you may actually save time! The original formulation didn’t have to concern itself with encodings because it wasn’t slicing strings. The original programmer didn’t even need to be aware that some characters are encoded with multiple bytes whereas others are encoded with a single byte. They didn’t even have to know what a byte was at all!
Food for thought.
At any rate, here’s a version that has lower cyclomatic complexity, preserves (in the constants) at least some indication of what the result will actually look like, and explains its algorithm reasonably well, if you understand percentages. I’ve included a comment to explain why we double the number of bytes to select from filled.
private static string GetPercentageRounds(double percentage)
{
const string empty = "⚪⚪⚪⚪⚪⚪⚪⚪⚪⚪";
const string filled = "🔵🔵🔵🔵🔵🔵🔵🔵🔵🔵";
var filledCount = (int)Math.Floor(percentage * 10);
var emptyCount = 10 − filledCount;
// Each 🔵 is two bytes in UTF-16
return filled[..(2 * filledCount)] + empty[..emptyCount];
}Polyfilling CSS with CSS Parser Extensions by Bramus
“To speed up the adoption of new CSS features, polyfills can be created. For example, the polyfill for container queries has proven its worth. However, this polyfill – like any other CSS polyfill – is not perfect and comes with some limitations. Furthermore, ±65% of the code of that polyfill is dedicated to parsing CSS and extracting the necessary information such property values and container at-rules from the CSS – which is a bit ridiculous.
“CSS Parser Extensions aims to remove these limitations and to ease this information gathering by allowing authors to extend the CSS Parser with new syntaxes, properties, keywords, etc. for it to support. By tapping directly into the CSS parser, CSS polyfills become easier to author, have a reduced size & performance footprint, and become more robust.”
The proposed syntax looks involved but I see the need for extending CSS support in older browsers. Even once it’s adopted, you will only be able to polyfill using the feature once the polyfill machinery is available in the browsers that lack the other CSS features that you’re actually polyfilling. That is, the missing features of today that need polyfilling will probably be available by the time this feature is made available—and it’s not even a W3C proposal yet—so we’re realistically about a decade out from being able to use this.
This reminds me of the Houdini APIs (MDN), which,
“Houdini is a set of low-level APIs that exposes parts of the CSS engine, giving developers the power to extend CSS by hooking into the styling and layout process of a browser’s rendering engine. Houdini is a group of APIs that give developers direct access to the CSS Object Model (CSSOM), enabling developers to write code the browser can parse as CSS, thereby creating new CSS features without waiting for them to be implemented natively in browsers.”
I’d written about Houdini way back in CSS and HTML Toolbox 2021. I don’t know how this necessarily differs but I trust that Bramus knows about Houdini and has determined that it’s not the same thing.
Cloud development doesn't have to be painful, thanks to .NET Aspire by Maddy Montaquila (YouTube)
A commentator asked why they would use Aspire instead of something like “minikube” (which is, apparently, a solution based on Kubnetes). As I understand it, Aspire is for projects that don’t already have minikube. Aspire’s strength for .NET solutions is the strongly typed configuration, the dashboard, etc. If you’ve already built a similar solution, then you probably don’t need Aspire. Or maybe you could benefit from the higher level of abstraction and type-safe configuration. Aspire is for solutions that wouldn’t be as organized about configuration and deployment because it’s complex and very specific knowledge.
The latest version includes support for Aspire-CLI and deployment to cloud-based environments rather than just running locally.
CSS makes sense when you realize it's a collection of algorithms by Kevin Powell (YouTube)
This is a nice explanation of how CSS is a declarative language, where you describe the metadata of your styles. The layout algorithm determines which property values affect the size and position of the element. Generally the properties position and display properties determine which layout algorithm is used for a given element. The layouts are,
- Normal flow layout (MDN) (selected by default)
- Inline layout (MDN) (selected by default for inline elements)
- Flexible box layout (MDN) (selected with
display: flex) - Grid layout (MDN) (selected with
display: grid) - Inline layout (MDN) (selected with
display: grid) - Multi-column layout (MDN) (selected with
display: grid) - Positioned layout (MDN) (selected with
display: grid) - Flow layout (MDN) (selected
float: leftorfloat: right)
Most properties work the same in all layouts. Some properties only have an effect in a specific layout mode, e.g., grid-template-columns is ignored if the layout is not grid. Other properties are interpreted differently or completely ignored depending on layout mode, e.g., width and margin are ignored in the inline layout.