Links and Notes for November 21st, 2025
Below are links to articles, highlighted passages[1], and occasional annotations[2] for the week ending on the date in the title, enriching the raw data from Instapaper Likes and Twitter. They are intentionally succinct, else they’d be articles and probably end up in the gigantic backlog of unpublished drafts. YMMV.
[1] Emphases are added, unless otherwise noted.↩
[2] Annotations are only lightly edited and are largely contemporaneous.↩
Table of Contents
- Public Policy & Politics
- Journalism & Media
- Economy & Finance
- Science & Nature
- Environment & Climate Change
- Medicine & Disease
- Art, Literature, Music, & Cinema
- Philosophy, Sociology, & Culture
- Technology & Engineering
- LLMs & AI
- Programming
- Fun
Public Policy & Politics
What Is Really Happening in Venezuela? US Attacks and Economic Situation Explained by Ben Norton (Scheer Post)
“Economically, Venezuela has suffered extreme hardship under illegal US sanctions and an economic embargo, which has blocked Venezuela from accessing the US-dominated international financial system and prevented Venezuela from exporting its oil and fixing/updating its oil infrastructure, causing government revenue to shrink by a staggering 99% (according to the top UN expert on sanctions, the special rapporteur Alena Douhan).”
“The Syrian government fell in part because the US/EU “Caesar” sanctions had devastated the economy. Syria could not get access to hard currency, and thus had very high inflation. The Syrian military was unable to pay its officers and soldiers, so they were not willing to fight. There were also shortages of food and oil. Syria was blocked from accessing its oil and wheat fields, which were militarily occupied by the US.”
“[…] the vast majority of the technology and oil infrastructure that had been used in Venezuela for the past century had been designed by Western companies. The oil industry had been nationalized by Chávez, but the technology it relied on was still the intellectual property of US and European corporations. So the sanctions prevented Venezuela from repairing its oil equipment and buying the new machinery needed to maintain and modernize its oil infrastructure. This caused a huge fall in Venezuela’s petroleum output.”
The ‘emergency’ that demanded huge tariffs on Swiss imports is now over. So what was the emergency? by Eric Boehm (Reason)
“Switzerland had minuscule tariffs (an average rate of 0.2 percent) on American imports. As I pointed out at the time, if Trump were seeking “reciprocal” tariffs with the Swiss, he would have to lower America’s tariffs rather than raise them. For another: The very existence of a U.S. trade deficit with Switzerland (which totaled $38.3 billion last year) seemed to undermine the entire logic behind Trump’s trade war. If having higher tariffs than your trading partner was the secret to ending trade deficits, as the Trump administration seems to believe, then why did America have a trade deficit with a country like Switzerland in the first place?”
“There are two possibilities here. You can believe that the vaguely defined economic emergency that required such huge tariffs on Swiss imports is already over, just a few months after those tariffs were imposed and despite the trade deficit seemingly growing rather than shrinking. If so, then you have to accept that Americans peacefully exchanging their money for chocolates, drugs, and watches were somehow undermining America’s economic security for years—but that those exact same transactions are now totally fine, because of the higher tariffs that no longer exist.”
UNREDACTED: Trump vs. China Is Not What You Think! by Lee Camp (YouTube)
Something something leftists are violent, amiright? (Reddit)
 Marjorie Taylor Greene hires security now that the right hates her
Marjorie Taylor Greene hires security now that the right hates her
“Marjorie Taylor Greene has been hated by the left for years and never feared for her life. She’s been hated by the right for two days and had to hire security.”
And here comes Trump’s most fervent defenders to say that they have always been at war with Eastasia: Average IQ In Congress Expected To Rise Significantly After MTG Resigns (Babylon Bee). While it is fair to say that she is not the sharpest tool in the shed, the Babylon Bee only notices when they’ve been ordered to by their masters in the White House. They’d never had a bad word to say about her before, despite ample satirical opportunity.
From a friend:
“She is resigning one day after her pension for life is locked in. And now she can unshackle herself from the lousy $174k year Representative salary and go full-on into media contracts. She has built her brand. Now to go cash in on it.”
Yeah, this is the consensus, and the evidence supports it. She’s made about $21M so far, which is a great start. She’s quitting two days after the pension starts, so that’s locked in for life, giving her the $174K per year as “rent” collected from the government. She’s all set. No need to be bothered with actual obligations to icky constituents anymore. There’s no need to consider her reasons, as they’re going to be whatever she needs to say to keep whatever grifts she plans on doing next viable. Grifter gonna grift.
And part of her next grift is definitely going to be bitching about social-welfare programs and handouts. I mean, obviously, right? If too much money goes to the poor and needy, there won’t be enough left over for poor Marjorie. She’s gotta look out for number one.
Israel Moved Gaza’s Yellow Line And Then Shelled Palestinians For Being On The Wrong Side by Caitlin Johnstone (Substack)
“Right wingers think a mother should be at home raising her children, an arrangement that many mothers would be on board with, but if you say this requires either state support or for employers to be forced to increase pay so that single-income families can exist they say “No that’s socialism!”
“They want the mothers to stay at home while the fathers work 80-hour work weeks for ten bucks an hour so that billionaires can become trillionaires.”
“OpenAI reportedly plans on building 250 gigawatts of capacity by 2033 to use for its energy-consuming servers, about the same amount of electricity that’s used by 1.5 billion people in India.
“So, no. No to this. Your right to extend your fist ends at my nose. You don’t get to just add this giant burden to the already severely overburdened ecosystem we all depend on for survival in order to expand your chatbot project. The collective is entitled to stop you. By force.”
While I agree with Caitlin’s sentiment here, she can be reassured that they’ve yet to build the first gigawatt. So take this all with a grain of salt.
A Palestinian Boy Waited for His School Bus. An Israeli Soldier Fired a Tear-gas Canister in His Face by Gideon Levyand Alex Levac (Haaretz)
“The door of the last jeep opens, the driver aims his rifle at the boy who’s holding the cookie. From a range of less than five meters he fires a tear-gas canister straight into the child’s face. A cloud of gas spreads, it’s hard to see anything.
“As the cloud dissipates the picture gradually comes into focus. The boy is lying on the ground, blood streaming from one eye, dangling from its socket, and from his nose.”
“The military convoy arrived from the neighboring village of Deir Samet, Rula says. The vehicles slowed down but did not come to a complete stop when the door of one jeep opened and the projectile was fired. After the incident Reina told her mother that when the driver aimed his weapon, the soldier sitting next to him grabbed the steering wheel. They didn’t utter a word.”
What, My Lai? by Scott H. Greenfield (Simle Justice)
“What is clear, coming out of the Nuremberg trials of the Nazi high command following World War II, is that “just following orders” is not a defense. While the high command alone bears responsibility for commencing illegal aggression, the soldier bears responsibility for how he executes his orders in the field.”
America Wants To Attack China With Japan by Indrajit Samarajiva (Indica)
“Remember, always, that Japan is not supposed to have an offensive military because they were so fucking offensive in WWII, especially against China. Something like 20 million Chinese were killed in WWII, and it weren’t Germans. Japan raped and tortured through East Asia, even bombing Sri Lanka for good measure. When it came to rape and torture, they did it with Japanese attention to horrific detail, just ask the Koreans. Americans do not know this because they didn’t make movies about it, but Japan’s neighbors never forget, least of all China.”
“[…] you are not a real country if you have some other country’s military bases on your soil. You are literally occupied, and calling it an alliance is just a hostage smiling for a photograph. America literally nuked Japan twice, completely civilian targets, a war crime if there ever was one and has occupied them ever since, using them to attack Korea and Vietnam and now to threaten China. Talking about Japan’s strategy is like asking my foot where it’s going.”
“The first point is that Japan has to be involved in any Taiwan War. If Japan is neutral, Taiwan (meaning America’s paw) loses completely. I cannot overstate how integral Japan is to any American aggression against China using Taiwan. According to the CSIS “the ability to operate from U.S. bases in Japan is so critical to U.S. success that it should be considered a sine qua non for intervention [in Taiwan].””
On the only available war-gaming scenario for a war for Taiwan:
“The ‘winning’ scenario for America also leaves the US taking heavy losses that they cannot politically bear outside of simulations. “In all iterations of the base scenario, U.S. Navy losses included two U.S. aircraft carriers as well as between 7 and 20 other major surface warships.” But Japan takes it much worse, because they’re the forward base, with the Americans egging them on.
“As the report says “The JMSDF suffered even more heavily, as all its assets fall within the range of Chinese anti-ship missile systems.” And what happens to Taiwan? It is left as “a damaged economy on an island without electricity and basic services.” This is all called winning by the Americans, which shows how little it is about the people they’re supposedly defending. The business model remains the same, even as the Empire collapses in shame. Light the world on fire and sell gasoline.”
In The Wake of The National Guard Killing, One Question Can’t Be Asked by Lee Camp (Truth & Freedom)
“While the man who killed the National Guard member will be severely punished and possibly executed, there will be no punishment for the bought-off politicians who do the bidding of our morally bankrupt corporate America. These politicians and the CEOs they serve are purveyors of violence. They trade in, produce, and reap violence. Meanwhile, they sit on mountains of money — the obscene profits from feeding American lives into the death machine of unfettered capitalism.
“All violence is not equal. Some of it is profitable and protected by our society. That kind of violence is the American way.”
Journalism & Media
Merz’ Friseur und Söders Selbstverblödung – egal, wir zahlen by Jens Berger (NachDenkSeiten)
“Rechnet man die Ausgaben für die privaten Fotografen, Visagisten und Friseure des Bundeskabinetts hoch, kommt man auf die stolze Summe von 690.000 Euro pro Jahr. Das dürfte ungefähr den Kosten für acht Lehrer, Polizisten oder Sozialarbeitern entsprechen. Bezahlt vom Steuerzahler. Doch wofür? Zumindest mir wäre ein Minister lieber, der „wie ein Totengräber“ aussieht und vernünftige Dinge sagt und eine vernünftige Politik verfolgt. Und was ikonische Bilder angeht, waren die privaten Schnappschüsse von Willy Brandt ohnehin besser und authentischer als alle nervigen inszenierten Bilder von einem mampfenden Markus Söder zusammen.”
“Natürlich – gemessen an den absurden Milliardensummen, die die professionell gestylten und inszenierten Damen und Herren für die Rüstung ausgeben, sind die Kosten für Visagisten, Friseure und Fotografen in der Tat Peanuts. Der eigentliche Skandal sind daher auch gar nicht die Kosten selbst; sondern die Selbstverständlichkeit, mit der dieser volksferne Narzissmus der Politikeliten heutzutage angesehen wird.”
Republicans astroturfed themselves by Ryan Broderick (Garbage Day)
“[…] from where I’m sitting, all this isn’t proof that shadowy foreign actors are destroying America. It’s proof that the American right has spent better part of the last decade letting algorithmic spam tell them what they want to hear, astroturfing themselves into believing that some silent majority out there believes in their worthless MAGA crusade. When all they were doing was chasing the approval of faceless accounts who realized their political movement was so hollow, so braindead simple, so spiritually worthless that they could easily earn a few Musk bucks by posting AI-generated photos of blonde women in American flag bikinis promising a Thousand Year Burger Reich.”
Economy & Finance
Booming tech sector wants govt intervention for ‘national security’ by Stavroula Pabst (Responsible Statecraft)
“Authors of a new Council on Foreign Relations report are framing government subsidies and bailouts for key tech industries as a national security imperative. Not surprisingly, many of the report’s authors stand to benefit financially from such an arrangement. Published last week, the report, titled U.S. Economic Security: Winning the Race for Tomorrow’s Technologies, urges, among a range of measures to build and onshore the sector, that “government intervention in the economy in the name of national security is most clearly warranted in cases of market failure.””
These people don’t even bother hiding the grift. They are the same ones who scream, with hair afire, that communism will be the end of humanity as we know it, but can also, with a straight face, argue that state-funded private monopolies in which they are invested and stand to handsomely profit, are necessary. Alles klar.
There is no need to point out the hypocrisy. They’re not hypocrites. They just think that they are entitled to try to make the world give them free things. They strongly believe that other people don’t deserve free things because those people are not themselves. It’s a consistent worldview: the world is here to serve them, not the other way around. Their aim is to extract value without compensation. Anyone else attempting to do so is necessarily impinging on their right to do so, so they should be stopped. They don’t care about fairness or justice. Their definition of justice is that they get what they think they deserve, for free and without effort.
Private Markets Are the New Securities Fraud by Matt Levine (Bloomberg)
“Here is “Private Equity, Public Capital and Litigation Risk,” by Ludovic Phalippou and William Magnuson:”“[…] This Article argues that this retailization of private equity creates a significant regulatory gap. Practices normalized in institutional settings — misleading performance metrics, manipulable valuations, opaque fees, limited liquidity, and fiduciary duty waivers — become significant litigation risks when ordinary investors enter the picture. Financial regulators are ill-equipped to address these risks, a problem exacerbated by the deregulatory agenda of the last two decades. But while public enforcement is likely to remain ineffective, private equity’s retailization opens a new and potentially more powerful avenue for holding firms to account: private enforcement. By broadening their investor base, private equity firms have exposed themselves to litigation under a wide range of domains, from contract to tort, from fraud to consumer protection. These doctrines, long thought peripheral to private equity, are often broader and stricter than traditional securities regulation.
“[…]
“As retail exposure to private equity has grown, the line between stylized financial storytelling and actionable fraud has narrowed. Displays of internal rates of return that might once have passed as harmless exaggeration, for example, may soon fall on the wrong side of the fraud line.
“Indeed, it is precisely these kinds of discrepancies—between public statements and economic reality—that fraud law is designed to address. Deceptive devices and affirmative misrepresentations are impermissible, under Rule 10b-5, under the Investment Company Act of 1940 and under the SEC’s marketing rule applicable to registered investment advisers. Private equity funds have largely avoided these regimes, or at least litigation under them, by virtue of limiting their marketing to qualified purchasers.”
“
“[…] it might be the case that, in the US, the cost of access to retail capital might be not so much “you have to follow public disclosure rules” but rather “you’re going to get sued a lot.””
“Financial markets impose a layer of abstraction between the real-economy people who need to know the weather and the meteorologists coming up with good weather models. In practice, if you build a fantastic new weather model, you should sell it to a hedge fund, and then the hedge fund will use that model to make commodities and power markets more efficient so that price signals will trickle back to the farmers and utilities.”
I know this is tongue-in-cheek but man, there are way too many people nodding along to that, thinking that this is really the only, most-efficient way to run things—with a hedge fund / private capital as the logical intermediary and ultimate arbiter for every last thing in society.
“If you’re a hedge fund and you think there’s a much greater than 25% chance that all the tariffs will be refunded, you should buy as much of this stuff as you can. But if you’re a hedge fund and you think there’s a much lower than 10% chance that all the tariffs will be refunded, you should sell as much of it as you can. But: Can you? You don’t import anything; you have no tariff refund claims of your own lying around to sell. You want to sell them short, to speculate. Is there a synthetic tariff refund trade? A naked short tariff refund trade? A swap referencing some unrelated importer’s tariff refund claim?”
Again, kinda sorta tongue-in-cheek but you absolutely know that there are thousands of people working on this right now.
“But can it drive the car? Like in a sense the really naive sci-fi future that you might want is not “autonomous car quietly drives itself” but rather “C-3PO complainingly squeezes himself into the driver’s seat of a normal car, turns the key in the ignition, grabs the steering wheel and merges onto the highway while fretting about traffic.” It will be very pleasing — for me, not necessarily for the car owners — if Tesla’s self-driving ends up being “you buy a humanoid robot and it drives your car while you sit in the back seat avoiding eye contact.””
That sounds way cooler, honestly.
On Benchmark Games, Gemini, and Declining Returns to Scale by Paul Kedrosky
“Until we know we are wrong, being wrong feels exactly like being right”
—Kathryn Schulz (Being Wrong: Adventures in the Margin of Error)
“The above table [of Gemini’s latest results] shows relatively small gains on tests where all leading models already cluster tightly. As a rule of thumb in a non-deterministic domain, most people don’t notice gains of less than 50%.
“These gaps, as a result, do not translate into different behavior for typical users. Minor shifts on saturated tasks do not change how a model reasons, follows instructions, writes code, or handles multi-step problems. When people interact with these systems, prompt phrasing, conversation history, and other sources of randomness matter more than small gaps on polluted benchmarks.”
“The sub-linear improvement of large language models at super-linear cost improvements remains the dominant feature.”
Global Capitalism: Affordability: Why So Much Costs Too Much and What to do About it by Democracy At Work | Dr. Richard Wolff (YouTube)
This is an excellent and current lecture about macro-economics as she is in the real world.
AI bubble madness: Why Nvidia's market cap fell $600,000,000,000 in ONE DAY by Geopolitical Economy Report | Ben Norton (YouTube)
This is an excellent overview of the AI bubble, with an emphasis on NVidia.
The Economy After the September Jobs Report by Dean Baker (CounterPunch)
“[…] the 119,000 jobs reported for the month was stronger than most analysts had expected, including me. But this hardly implies robust job growth. We averaged 170,000 jobs a month in 2024, so now we’re supposed to be celebrating a report showing job growth that is 70 percent of last year’s average?
“But it gets worse. The prior two months’ data were both revised down. The average growth for the four months ending in September was less than 40,000. Furthermore, almost all the growth was in healthcare. Since May, the economy has added 174,000 jobs. The healthcare sector added 157,000 jobs, accounting for more than 90 percent of job growth over this period.”
“The controls fix the size of the population, but the number of people reported as foreign born is taken from the survey. This number has fallen sharply. Part of that is due to people being deported or choosing to leave. Part of the drop is due to people not answering the survey and part of it is due to people lying and identifying as native-born, which is understandable under the circumstances.
“Given the construction of the data, a drop in the number of foreign-born workers automatically leads to an increase in the reported number of native-born workers, since the total is fixed by the population controls. This means if Steven Miller took speed, stayed up all week, and deported every last foreign-born worker, the data would show an increase in native-born employment of 32,000,000.”
“The weakening of the labor market is bad news for tens of millions of workers who are trapped in their jobs and seeing lower real wages due to inflation. But it is not full-fledged recession stuff. That will have to wait for the collapse of the tech bubble.”
AI Capex Risk as Predictable Engineering by Paul Kedrosky
“A new interview with former OpenAI scientist Ilya Sutskever captures, almost accidentally and in passing, something important about the AI boom. It helps answer the question everyone asks: Why are companies willing to spend so much?
“The naive answer is that it is all about the perceived size of the AI opportunity. But that is uncertain, and captures only one side. What it misses is how, for a halcyon period, from 2017-2022, compute spending on AI had not only been derisked; it had turned into a predictable capability production function.”
compute + data + parameters + training = capability“This created a new kind of speculation, one that doesn’t feel like speculation. Pre-training scaling “laws” created the illusion of a physics-like production function: add compute, get capability. That belief is what has been driving a trillion-dollar capex cycle with no historical parallel. And now that the curve’s costs have soared and capabilities bent, we’re left with what increasingly looks the largest mispriced engineering bet in modern technology.”
Premium: The Hater’s Guide To NVIDIA by Ed Zitron (Where's Your Ed At?)
“Okay, well, let’s start with those racks. You’re gonna need to give Jensen Huang $600 million right away, as you need 200 GB200 racks. You’re also gonna need a way to make them network together, because otherwise they aren’t going to be able to handle all those big IT loads, so that’s gonna be another $80 million or more, and you’re going to need storage and servers to sync all of this up, which is, let’s say, another $35 million.
“So we’re at $715 million. Should be fine, right? Everybody’s cool and everybody’s normal. This is just a small data center after all. Oops, forgot cooling and power delivery stuff — that’s another $5 million. $720 million. Okay.
“Anyway, sadly data centers require something called a “building.” Construction costs for a data center are somewhere from $8 million to $12 million per megawatt, so, crap, okay. That’s $250 million, but probably more like $300 million. We’re now up to $1.02 billion, and we haven’t even got the power yet.
“Okay, sick. Do you have one billion dollars? You don’t? No worries! Private credit — money loaned by non-banking entities — has been feeding more than $50 billion dollars a quarter into the hungry mouths of anybody who desires to build a data center. You need $1.02 billion. You get $1.5 billion, because, you know, “stuff happens.” Don’t worry about those pesky high interest rates — you’re about to be printing big money, AI style!
“Now you’re done raising all that cash, it’ll now only take anywhere from 6 to 18 months for site selection, permitting, design, development, construction, and energy procurement. You’re also going to need about 20 acres of land for that 100,000 square foot data center. You may wonder why 100,000 square feet needs that much space, and that’s because all of the power and cooling equipment takes up an astonishing amount of room.
“So, yeah, after two years and over a billion dollars, you too can own a data center with NVIDIA GPUs that turn on, and at that point, you will offer a service that is functionally identical to everybody else buying GPUs from NVIDIA.”
“The single-largest, single-most-valuable, single-most-profitable company on the stock market has got there through selling ultra-expensive hardware that takes hundreds of millions or billions of dollars (and years of construction in some cases) to start using, at which point it…doesn’t make much revenue and doesn’t seem to make a profit.
“Said hardware is funded by a mixture of cashflow from healthy businesses (see: Microsoft) or massive amounts of debt (see: everybody who is not a hyperscaler, and, at this point, some hyperscalers). The response to the continued proof that generative AI is not making money is to buy more GPUs, and it doesn’t appear anybody has ever worked out why.”
EXCLUSIVE: Credit Report Shows Meta Keeping $27 Billion Off Its Books Through Advanced Geometry by Ryan Stohl (Life, Liquidity & Other Delusions)
This is a deeply sarcastic version of the credit report for a ~$28B funding vehicle that Meta has established for a campus of data centers. The gist is in the title: Meta owns and operates this thing outright but the liability is off of its books. While Meta is by any standard in control and responsible for the campus, it will technically belong to another, new entity, one which magically acquires a credit rating of A+ for what would otherwise be a wildly risky venture. The rating is based on the wink-and-a-nod acknowledgement that Meta does own it and the ownership structure reflects Meta’s desire to keep huge liabilities off of its own books.
This is all above board because this is just how the world works when you’re super-rich or, as the author puts it, “This treatment is considered acceptable because the people who decide what is acceptable have accepted it.”
“The Outlook is Superficially Stable, defined here as “By outward appearances stable unless, you know, things happen. Then we’ll downgrade after the shit hits the fan.””
“We assign a preliminary A+ rating to the notes, one notch below Meta’s issuer credit rating, reflecting the very strong contractual linkage to Meta and the tight technical separation that allows Meta to keep roughly $27 billion of assets and debt off its balance sheet while continuing to provide all material economic support.”
“The structure allows the Issuer to borrow money, earn interest on the borrowed money, and then use that interest to satisfy the equity requirement that would normally require… money.
“Nothing is created. Nothing is contributed. It’s a loop. Borrow money, earn interest, and use the interest to claim you provided equity. The kind of circle only finance can call a straight line.”
“Meta, through Pelican Leap LLC (Tenant), has entered into eleven triple-net leases—one for each building—with an initial four-year term starting in 2029 and four renewal options that could extend the arrangement to twenty years. The leases rely on the assumption that Meta will continue to need exponentially more compute power and that AI demand will not collapse, reverse, plateau, or become structurally inconvenient.
“The notes issued by Beignet are secured by Beignet’s equity interest in JVCo and relevant transaction accounts. They are not secured by the underlying physical assets, which remain at the JVCo and Landlord level. This is described as standard practice, which is true in the same way that using eleven entities to rent buildings to yourself has become standard practice.
“The resulting structure allows Meta to support the project economically while leaving the associated debt somewhere that is technically not on Meta’s balance sheet. The distinction is thin, but apparently wide enough to matter.”
“We did not model what would happen if data center demand collapses and Meta cannot secure a new tenant. This scenario was excluded for methodological convenience.”
“JVCo qualifies as a variable interest entity because the equity at risk is ceremonial and the real economic exposure sits entirely with the party insisting it does not control the venture. This remains legal due to the enduring belief that balance sheets are healthier when the risky parts are hidden.”
“Our interpretation is fully compliant with U.S. GAAP, which prioritizes the geometry of the legal structure over the inconvenience of economic substance and recognizes control only if the controlling party agrees to be recognized as controlling.”
“The economics are wedded to Meta’s credit profile, which we are required to describe as AA-/Stable rather than “the only reason this entire structure doesn’t fold from a stiff breeze.” Meta guarantees the rent, the RVG, and the continued relevance of the facility. The rest is décor auditors would deem “tasteful.””
“Being sticklers for tradition, and having learned nothing from the financial crisis of 2008, we treat the spreadsheet as the final arbiter of truth, even when the inputs describe a world no one lives in.”
“Our methodology interprets “contractually transferred” as “ceased to exist,” so we decline to model the risk of overruns on a $28 billion campus built in a hurricane corridor. This is considered best practice.”
“If consolidation rules ever evolve to reflect economic substance, Meta could be required to add $27 billion of assets and matching debt back onto its own balance sheet. Our methodology treats this as a theoretical inconvenience rather than a credit event, because calling it what it really is would create a conflict with the very companies we rate.”
“We set this concern aside because at this stage in the transaction, the A+ rating is a structural load-bearing wall, and we are not paid to do demolition.”
“If hyperscale supply balloons or the resale market for 2-gigawatt data centers becomes as illiquid as common sense, Meta will owe more money. This increases Meta’s direct obligations, which should concern us, but does not, because Meta is rated AA-/Stable and therefore presumed to withstand any scenario we have chosen not to model.”
“we expect the structure to hold together as long as Meta keeps paying for everything and the accounting rules remain generously uninterested in economic reality.
“We assume, with the confidence of people who have clearly not been punished enough […]”
“This report is intended solely for institutional investors, entities required by compliance to review documents they will not read, and any regulatory body still pretending to monitor off-balance-sheet arrangements. FSG LLC makes no representation, warranty, or faint gesture toward coherence regarding the accuracy, completeness, or legitimacy of anything contained herein. By reading this document, you irrevocably acknowledge that we did not perform due diligence in any conventional, philosophical, or legally enforceable sense.”
“Any resemblance to objective analysis is coincidental and should not be relied upon by anyone with fiduciary obligations, ethical standards, a working memory, or the ability to perform basic subtraction. Forward-looking statements are based on assumptions that will not survive contact with reality, stress testing, most Tuesdays, or a modest change in interest rates.”
“Readers who discover material errors in this report are contractually obligated to keep them to themselves and accept that being technically correct is the least valuable form of correct.”
Science & Nature
“In linguistics, reduplication is a morphological process in which the root or stem of a word, part of that, or the whole word is repeated exactly or with a slight change.
“The classic observation on the semantics of reduplication is Edward Sapir’s: “Generally employed, with self-evident symbolism, to indicate such concepts as distribution, plurality, repetition, customary activity, increase of size, added intensity, continuance.” It is used in inflections to convey a grammatical function, such as plurality or intensification, and in lexical derivation to create new words. It is often used when a speaker adopts a tone more expressive or figurative than ordinary speech and is also often, but not exclusively, iconic in meaning.”
“In Swiss German, the verbs gah or goh “go”, cho “come”, la or lo “let” and aafa or aafo “begin” reduplicate when they are combined with other verbs.
“Si chunt üse Chrischtboum cho schmücke.”
In English: “she’s coming to come decorate the Christmas tree.” I can hear people from Central NY saying something like that.
Environment & Climate Change
Cyclone Ditwah Hits Sri Lanka by Indrajit Samarajiva (Indica)
“Sri Lanka lives and dies by the regular monsoon, where the ocean breeze blows across the subcontinent, hits the Himalayas and rebounds as rain. The slow cycle gives us two growing cycles and sustenance that the ancients learned how to trap in giant tanks (let not a drop go to the sea without being useful to man[3]). But Sri Lanka just dies by the irregular cyclone, it has wiped out our harvest this year and people will go hungry, I fear.”
“It’s strange encountering such creatures. We’re so used to being apex predators. But we still can’t control the weather. We moderns think we’re gods because we have smartphones, but we’re only good for recording the movements of the old gods. Sun and wind, thunder and rain. Indra, whom my namesake (Indrajit) trapped once, but who[m no] human has ever captured. Like I say, I don’t know if I believe in God (they/them), but I sure fear them. And right now, outside my blinds, I sure can hear them.”
[3]
This line was uttered by Parakramabahu I (Wikipedia),
↩“Parākramabāhu I (Sinhala: මහා පරාක්රමබාහු, c. 1123–1186),[2] or Parakramabahu the Great, was the king of Polonnaruwa from 1153 to 1186. He oversaw the expansion and beautification of his capital,[3]: 7 constructed extensive irrigation systems, reorganised the country’s army, reformed Buddhist practices, encouraged the arts and undertook military campaigns in South India and Burma”
Medicine & Disease
White House Reclassifies Nursing As Hobby (The Onion)
“There’s a lot of cutting and sewing in nursing, so it’s really an activity that falls under arts and crafts. Some moms choose to knit, others choose to nurse. Plus, rushing between ER patients is a great way to stay active, just like riding your bike. And what’s also great is you get to brush shoulders with doctors, who can give you career advice should you choose to pursue a real job in the medical world some day.”
Art, Literature, Music, & Cinema
Using the Night by Mark Iosifescu (n + 1)
“Such moments flow freely through the endearingly weird Shadow Ticket, which doesn’t so much reprise the 88-year-old Pynchon’s longstanding writerly proclivities as condense them, squishing a lifetime’s worth of narrative moves into his lowest pagecount since The Crying of Lot 49. Maybe you know the drill: metahistorical intrigue and antiauthoritarian politics; several deep benches’ worth of quirky characters toting loudly emblematic affectations and not-strictly-probable names; song-and-dance numbers with rhythmically typeset lyrics and toy instrument arrangements, plus screwball wordplay and cartoon pratfalls and gags, gags, gags.”
“Shadow Ticket, in addition to being extremely fun and almost indecently readable, is also replete with edges left conspicuously unsanded, a combination that might go some way toward frustrating or at least reframing the prevailing misconception of Pynchon as a willfully difficult, high-maximalist, paranoid outsider-recluse.”
“[…] the all-time bangers The Crying of Lot 49 (1966) and Gravity’s Rainbow (1973), would see Pynchon refine and vary his thematic and stylistic approaches by many extraordinary degrees, but the sinister conspiratorial frameworks enumerated by the novels ultimately double down on those “shadowy visions,” prewar and otherwise. Theirs is a world-historical conceptualization of tremendous instructive value (one whose conclusions have, needless to say, spent the last fifty-odd years getting proven righter by the day); they are also the reason that reader fetishes for concealed meanings, pattern recognition, and “paranoia”—as a contextless abstraction—have been irreducible features of Pynchon’s fandom ever since.”
“Gravity’s Rainbow, for instance, posits a hard binary between “the Elect” and “the Preterite”: categories borrowed from Calvinist theology, repurposed within the novel’s putatively comprehensive world-system to denote those whom our power structure rewards and those whom it grinds underfoot.”
“The knitting machines which provoked the first Luddite disturbances had been putting people out of work for well over two centuries. Everybody saw this happening—it became part of daily life. They also saw the machines coming more and more to be the property of men who did not work, only owned and hired. It took no German philosopher, then or later, to point out what this did, had been doing, to wages and jobs. . . . What gave King Ludd his special Bad charisma, took him from local hero to nationwide public enemy, was that he went up against these amplified, multiplied, more than human opponents and prevailed. When times are hard, and we feel at the mercy of forces many times more powerful, don’t we, in seeking some equalizer, turn, if only in imagination, in wish, to the Badass—the djinn, the golem, the hulk, the superhero—who will resist what otherwise would overwhelm us?”
Damn that last line is a perfect description of why I liked The Equalizer.
“The Luddite essay (which goes on, remarkably, to anatomize the Gothic novel, condemn the contemporary military-industrial complex, and finish off with a warning about the AI bubble?!) was published, as mentioned, in 1984. There’s plenty to say about Pynchon’s evident love for Orwell; he even penned an admiring foreword to a “centennial edition” of 1984 in 2003. But the dateline might be most relevant for its role in Vineland, which dropped in early 1990 but takes place six years prior. By the mid-’80s—with Reagan having taken 49 states for reelection and Dynasty #1 on the Tube ratings—it was clear that whatever promises of countercultural Badassery the 1960s had held were being violently rolled back.”
“So here’s Pynchon now: nearly 90 years old, having oracularly diagnosed more than half a century of American life in a wide variety of accents, and three novels deep on a run of oddly shaped mysteries in which his pulpiest style exercises share space with undisguised sentiment, a lightly worn leftism, and a loose interweave of uncertainties.”
“There’s a deeper strangeness, too, in Shadow Ticket’s tendency toward radical compression, in its feeling of Pynchon pulling his usual moves on something of a speedrun basis. Sentence by sentence, entire histories and relationships are related via one or two lines of semi- or unattributed dialogue, while whole conversations, densely laid-in with arch hepcat slang and flirty barbs, go by as pure transcript without any solid grounding in physical space or time.”
Sounds like Gaddis’s J R.
“What it is, though, is somehow unsettled: a book in which, even as narratives fracture, tonal centers fail to hold, and mysteries go unsolved, something like justice has just enough time to make itself known before the clock runs out—as in, not-altogether-coincidentally, the moment of “the last delta-t” that closed the author’s best-known and most rigorously analyzed novel. That book, of course, featured another ragtag Counterforce, a group of far-flung rebels scampering across history toward a long-deferred redemption, “using the night, and their own solidarity and discipline, to achieve their multiplications of effect.””
Disclaimer before old Warner Bros. cartoons (Reddit)
 Disclaimer before old Warner Bros. cartoons
Disclaimer before old Warner Bros. cartoons
“The cartoons you are about to see are products of their time. They may depict some of the ethnic and racial prejudices that were commonplace in American society. These depictions were wrong then and are wrong today. While the following does not represent the Warner Bros. view of today’s society, these cartoons are being presented as they were originally created, because to do otherwise would be the same as claiming these prejudices never existed.”
Do I use AI for writing? No. Never. I don’t feel the need. I can write. I enjoy writing. I write too much already. I am confident that what I write expresses my thoughts well. I do not ever wonder whether a machine could formulate my thoughts better than I can.
I learned to write in a world without LLMs. I am one of the people whose data was plundered to feed to the machines that you now use to emit texts that are pale shadows of what—after so much practice and effort and blood, sweat, and tears—flows naturally from my fingertips..
I already have my own voice. I already know how I want to write what I’m thinking. Nothing the LLM can suggest would sound like me.
I do not need the machines for writing. I do not use them for writing.
I am John Henry.
Philosophy, Sociology, & Culture
Why We Remain Alive Also In A Dead Internet by Slavoj Žižek (Žižek Goads and Prods)
“I often repeat a joke about how today, in the era of digitalization and mechanical supplements to our sexual practices, the ideal sexual act would look: my lover and I bring to our encounter an electric dildo and an electric vaginal opening, both of which shake when plugged in. We put the dildo into the plastic vagina and press the buttons so the two machines buzz and perform the act for us, while we can have a nice conversation over a cup of tea, aware that the machines are performing our superego duty to enjoy. Is something similar not happening with academic publishing? An author uses ChatGPT to write an academic essay and submits it to a journal, which uses ChatGPT to review the essay. When the essay appears in a “free access” academic journal, a reader again uses ChatGPT to read the essay and provide a brief summary for them—while all this happens in the digital space, we (writers, readers, reviewers) can do something more pleasurable—listen to music, meditate, and so on.”
The discussion begins with the text in the picture attached to the post.
“Kant never left his home town, Koenigsberg (today’s Kaliningrad), never married, never changed his daily schedule or his diet, and died, presumably happy and mildly bored, at the age of 80. His last words were: “It’s fine.””
Some of Reddit’s finest emerged from beneath their rocks to ply their trade.
“One must imagine Kant happy”“Don’t be absurd, virgins can’t catch Sisyphus.”
These two refer to Camus’s essay Le mythe de Sisyphe (The Myth of Sysiphus) (Wikipedia), wherein he concludes that “[t]he struggle itself towards the heights is enough to fill a man’s heart. One must imagine Sisyphus happy.” It is a profound statement that anchors absurdism. I am deeply enamored of its simplicity and power.
“And people pretend autism was invented in the last 30 years.”“The funniest comment I read about him is that his routine was so precise that people used the time he passed in front of their house in his morning walk to calibrate the watches they had.”“A day passed where he doesn’t appear “Someone check on the egghead immediately””“Maybe they built an 8th bridge in koenigsberg and he got stuck in a loop”
This comment chain ends in a reference to Euler’s Seven Bridges of Königsberg (Wikipedia), which is,
“[…] a historically notable problem in mathematics. Its negative resolution by Leonhard Euler, in 1736, laid the foundations of graph theory and foreshadowed the idea of topology.”
This brings back memories of my university days, where we discussed this exact problem both in Graph Theory my second year and in a Topology Seminar in my fourth.
Someone else cited The Age of Revolution, pg. 61,
“The capture of the Bastille, which has rightly made July 14th into the French national day, ratified the fall of despotism and was hailed all over the world as the beginning of liberation. Even the austere philosopher Immanuel Kant of Koenigsberg, it is said, whose habits were so regular that the citizens of that town set their watches by him, postponed the hour of his afternoon stroll when he received the news, thus convincing Koenigsberg that a world-shaking event had indeed happened.”“The strangest thing about Kant was that he wasn’t always like this. He had a comperatively rowdy time as a student who like to party and get drunk.
“But once he started on his philosophical quest he saw the amount of work before him and the great importance of that work led him to completely change his life to get as much of it done as possible. Sadly, he was not able to finish before dementia took root.
“In other words, the way Kant lived is seen as a fun bit of trivia today but chances are that to Kant it was a great sacrifice that he was willing to make. That’s why he was overjoyed when he heard that the revolution succeeded because to him there wasn’t much of a difference in what they [he and the French] actually wanted to achieve.”
Finally, much lower, there was a chain of a dozen comments reciting the lyrics to Bruces’ Philosophers Song (Wikipedia)
“Immanuel Kant was a real pissant
Who was very rarely stable“Heidegger, Heidegger was a boozy beggar
Who could think you under the table“David Hume could out-consume
Wilhelm Freidrich Hegel“And Wittgenstein was a beery swine
Who was just as schloshed as Schlegel“There’s nothing Nietzsche couldn’t teach ya
‘bout the raising of the wrist
Socrates, himself, was permanently pissed“John Stuart Mill, of his own free will
On half a pint of shandy was particularly ill“Plato, they say, could stick it away
Half a crate of whiskey every day“Aristotle, Aristotle was a bugger for the bottle
Hobbes was fond of his dram“And Rene Descartes was a drunken fart
“I drink, therefore I am.”“Yes, Socrates himself is particularly missed
A lovely little thinker, but a bugger when he’s pissed”
It’s even better when sung (1:00)
Bruce's Philosophers Song (Bruce's Song) {Official Lyric Video] by Monty Python (YouTube)
God, I remember listening to this song so many times on my two-cassette copy of Monty Python’s The Final Rip Off (Wikipedia). It’s where I heard most of these philosopher’s names for the first time. My friends and I had it memorized and were not unlikely to belt it out whenever and wherever, right before we were chased all the way home by bullies.
As evidenced by this blog, my propensity for being a target for bullying is unchanged.
Even further down is a comment that reads,
“That’s not Kant, that’s Friedrich Heinrich Jacobi in the picture.”
The linked article says that “the […] image, widely used to depict Kant, is not an image of Kant,” and offers a ton of supporting documentation.
A final comment (correctly) quibbled with the translation,
“His words were “Es ist gut.” and those carry a very different mood than the words that were here chosen as a translation.”
That’s true. Good is better than fine. It is a statement of being pleased with life and one’s place in it, with one’s accomplishments. “Good” is high praise from someone from the DACH region—the German-speaking region comprising Germany [D], Austria [A], and Switzerland [CH]—where we usually stop at nöd schlecht or nicht schlecht and never make it to guet or gut.
To close, a final comment that writes, “Kierkegaard […] said the best life is boring but you’re not bored by it,” which I also very much like.
Warum sind es immer die Männer, die wie ein Haufen Geburtsfehler und sonstige genetische Benachteiligungen in Menschenform gegossen aussehen, die über die angeblichen Schwächen der Frauen diskutieren wollen?
I thought of it in German but it translates to:
Why is it always the men who look like a pile of birth defects and other genetic deficiencies shaped like a person, who want to discuss the supposed weaknesses of women?
State law requires Tennessee public school teachers to teach gun safety starting in kindergarten by Milo Stevens (WSWS)
“The manual itself divides instruction into three distinct grade ranges: K-2; 3-5; 6-12. The first two grade groupings primarily focus on familiarizing children with firearm nomenclature, identifying the difference between a toy and a real firearm, and the importance of telling an adult if a child finds a firearm. The third grade grouping focuses on teaching “All family members” “safe gun handling” and including the proper storage of firearms and ammunition.”
The U.S. military needs your sons and daughters too. There’s lots of work to do.
I had just finished watching a short video from German kids TV that was browbeating/indoctrinating kids into thinking that obligatory military service is a good idea because “wanting to live in a country without being willing to defend it is egoistic.” Cool, cool, cool. Be happy that the U.S. isn’t the only western country hurtling toward full-blown military authoritarianism. We are all North Korea now I guess.
The video was mentioned in this article: War propaganda and militarism on children’s TV in Germany by Martin Nowak (WSWS)
“The moderator’s rhetorical tricks were reminiscent of the repulsive methods with which conscientious objectors were confronted in the past. With a focus on emotional appeals, the causes of war, rearmament and Bundeswehr deployments were completely left out. In the end, Rizkallah staged an apparent compromise: everyone would agree that one should give something back to one’s country—whether militarily or otherwise.”
This article is about a short video from German kids TV that was browbeating/indoctrinating kids into thinking that obligatory military service is a good idea because “wanting to live in a country without being willing to defend it is egoistic.” Cool, cool, cool. Be happy that the U.S. isn’t the only western country hurtling toward full-blown military authoritarianism. We are all North Korea now I guess.
Here’s the video. The kids defend themselves quite well, most especially the young women (brunette; lots of makeup) but all of them were reasonably well-spoken and pretty much anti-war. The guy had a lot of work to do but he was willing to do it.
Sollte es wieder einen verpflichtenden Wehrdienst geben? | logo! no.front | Schüler-Debatte by logo! (YouTube)
I sent this stuff to a good friend, who sagely replied (and I’m going to quote at length because it’s all very good stuff),
“[…] my knee jerk reaction to this is that that’s a weird state wide push, but there’s value in it. The knowledge of what a gun is, how to handle it, and where it should go is great to have. I’ve seen the infamous city slicker at a gun range waving it around like a professor with a pointing stick. You could extend this argument to say “should we make all our kids get drunk before they go to college so they don’t taste alcohol for the first time and do something crazy?” I think there’s value in that, akin to that of sex education.
“I’m not sure if I agree with the point that this is pushing militarism – more below on the palming off of policy change. I don’t trust a Tennessee republican more than I can throw them, but the article which was very left skewed was pulled excerpts out from the material to be taught that I think is decent for a kid to know. If a kid knows to put the safety on, treat a gun like it’s loaded and tell an adult about it, that’s great. Is this a baby seed that will bloom into a state that’s all too ready to March for its own cause, idk I sure hope not.
“Now where I think the article is right:”
- this is a palm off of policy change for sure. How do we blame workers when a forklift falls on them, we train them. How do we blame kids and schools for shootings, we train them.
- the funding bit is a sad reality. Crazy that the state would rather us know about guns than actual personal finance. And this is more curriculum for the same dollar to cover.
- I really think this is a push to make the people who give bill Lee happy and piss off the person who works in the cafe where I get my coffee. That isn’t at all meant to undersell this. We are so Fucking schism-ed that “oh the libs will hate this” is probably a huge selling point for a bill to, well, Bill
I now see that I utterly failed to continue this particular conversation, which I will have to rectify.
I can, of course, get behind the argument that there is “no such thing as bad knowledge”. And, therefore, it makes sense in a world that assumes that guns must exist in the numbers that they do, that kids gotta learn about these dangerous things. Because what else are you gonna do? We just literally can’t seem to get rid of ‘em or reduce their prevalence.
We don’t make that argument about a lot of other things, though. For a lot of other things, we make the world as safe as possible for kids. Rubber mats in playgrounds. Closing public swimming pools.[4] Not allowing kids outside without an escort.
Hell, we keep trying to dismantle encryption and keep trying to justify tracking every person’s click on the Internet in the same of stopping CSAM (Child Sexual Abuse Material).
Like, we are literally willing to sacrifice everything that gives most people even a modicum of freedom and privacy on the altar of protecting children, but we don’t consider restricting guns any more than they already are, despite the astronomical amount of harm done to children (astronomical relative to any other modern society, even those like Canada and Switzerland, which have the same or higher per-capita gun-ownership rates).
So the answer is that kids gotta learn about guns first thing because we are trained not to even consider any other possible solution.
I’m just picturing Big Bird showing kids how to check that the safety on a Glock.
The by-now accepted-as-human-nature predilection for enormous personal vehicles works on the same psychological dynamic.
Guns and trucks happen to be things that are economically advantageous for the war industry (get people accustomed to guns and violence) and the auto industry (get people accustomed to buying giant vehicles with enormous profit margins for the vendor). Monitoring everyone’s communications is also extremely lucrative so that’s why we keep seeing them using the sledgehammer of CSAM to get more access.
They bring out sledgehammers like CSAM when more subtle forms of propaganda don’t work. Like, why do people still love the police so much, despite it being completely obvious that they are no longer holding to a mission of “serving and protecting”?
Well, it’s not a coincidence that there are 40 CSI and NCIS shows, right? That’s their purpose: convince people that cops are generally good, that they generally don’t need warrants, that any laws restricting them are hamstringing them from catching bad guys. Oh, and that the category of “bad guys” is very clear, and does NOT include any members of the ruling class. There are shows that do NOT do this but that’s most of them.
Anything that doesn’t offer economic advantage or some way of encouraging people to allow themselves to be controlled isn’t important. That says a lot about a society.
How I View the US After 13 Years Living in Europe by Evan Edinger (YouTube)
“0:00 Hook & Intro
1:01 Why I Don’t Miss Guns
4:34 US Style Government vs European Style
7:07 Walkability and Public Transport
9:21 Food Quality and Price
10:36 Healthcare in the US vs Europe
12:04 Consumer Protections in the US vs Europe
12:52 Workers’ Rights in the US vs Europe
14:45 Don’t US Workers Earn More Money?
16:23 Do Americans Romanticise Europe Too Much?”
[4] My interlocutor never knew a world with public pools. I watched the States go from “every village has a public pool with diving boards and a deep end” to “get rid of diving boards” to “get rid of the deep end” to “cement the whole fucking thing over.” It was always with the argument that it was too hard to insure because it was too dangerous. So everyone got a private pool. What a surprise. That’s the American solution to everything. Get rid of anything communal and make everyone get their own. Then get guns to shoot anyone who comes on your property. You are correct that it will never be fixed but you will not dissuade me that it describes what I consider to be a dystopia.↩
Demolish or Defend? The Battle of Social Values by Professor Asma's Guide To Unusual Knowledge (YouTube)
How did Professor Asma end up discussing those with skin in the game without examining more closely what that actually means? It doesn’t mean that you want stability for the sake of your children or your elderly relatives. It means that you, either consciously or unconsciously, have a vested interest in maintaining the status quo. And your status quo is to be in the middle of the pile of turtles. But at least you’re not at the bottom.
You know that your world has the level of comfort that it does because a lot of other people don’t have that level of comfort. You know that it comes at their cost. But you teach yourself to ignore it, because it’s better for you that way. We can’t talk about “conservatives” and people who seek the safe option without talking about how those people do it because they have something to lose.
And the thing that they have to lose is that they’re leveraging an arbitrage opportunity over others who don’t have anything to lose—because society has already taken everything away from them, and continues to do so.
I can’t believe that he argued that people are willing to watch everything burn because it’s titillating, without even considering that those without skin in the game—those being farmed for his benefit—have, by definition, nothing to lose because everything has already been taken from them. For some, anything is better than what we have now, even a world on fire.
Technology & Engineering
NSA and IETF, part 2: Corruption continues by D. J. Bernstein (The cr.yp.to blog)
“In reality, IETF standardization is a denial-of-service attack. The only people who can keep up are people paid to participate. Instead of acknowledging the resulting bias and taking appropriate countermeasures, IETF pretends the problem doesn’t exist.
“I’ve been focusing on one incident of corruption of the IETF standardization process, but this isn’t an isolated example. Look at Peter Gutmann’s October 2025 slides blasting IETF as a “pay-to-play” standards organization and giving many concrete examples. Corruption is a money-maker; it’s not some sort of surprise.”
“Do these quotes sound like IETF participants using “their best engineering judgment to find the best solution for the whole Internet, not just the best solution for any particular network, technology, vendor, or user”? Or do they sound like NSA buying standardization?”
This is followed up on the same day by NSA and IETF, part 3: Dodging the issues at hand by D. J. Bernstein (The cr.yp.to blog)
“Normal practice in deploying post-quantum cryptography is to deploy ECC+PQ. IETF’s TLS working group is standardizing ECC+PQ. But IETF management is also non-consensually ramming a particular NSA-driven document through the IETF process, a “non-hybrid” document that adds just PQ as another TLS option.”
“I can understand not everybody being familiar with the specific definition of “consensus” that antitrust law requires standards-development organizations to follow. But it’s astonishing to see chairs substituting a consensus-evaluation procedure that simply ignores objections.”
“Notice how the “area director” is dodging Farrell’s point. If NSA can pressure the TLS WG into standardizing non-hybrid ML-KEM, why can’t China pressure the TLS WG into standardizing something China wants? What criteria will IETF use to answer this question without leaving the WG “open to accusations of favouritism”? If you want people to believe that it isn’t about the money then you need a really convincing alternative story.”
This is followed up on the same day by NSA and IETF, part 4: An example of censored dissent by D. J. Bernstein (The cr.yp.to blog)
“The IETF TLS working-group chairs issued “last call” on 5 November 2025 for objections to a particular document, the same controversial NSA-driven document that was also the topic of my earlier posts today, as if still-unresolved objections hadn’t already been raised before that. The deadline for objections is 26 November 2025.
“During this limited-time “last call” for objections. IETF management has censored a new objection that I’ve raised to this document. It’s fascinating to compare this to IETF’s claim to be “open to all interested individuals”; to IETF’s claim that “decision-making requires achieving broad consensus via these public processes”; and to the legal requirement of openness.”
“On 17 October 2025, they posted a “Notice of Moderation for Postings by D. J. Bernstein” saying that they would “moderate the postings of D. J. Bernstein for 30 days due to disruptive behavior effective immediately” and specifically that my postings “will be held for moderation and after confirmation by the TLS Chairs of being on topic and not disruptive, will be released to the list”.
“Do IETF procedures allow WG chairs to censor a participant for unspecified “disruptive behavior”? No. The procedures cited by the chairs, RFC 3934, do allow censorship by chairs, but only for behavior that the chairs claim is “disruptive to the WG process”. There has been no such claim, nor would such a claim be defensible.
“The IETF WG procedures say that conflicts “must be resolved by a process of open review and discussion”. Filing objections is following this process, not disrupting it. Sure, NSA is unhappy whenever any of its efforts to sabotage standards are disrupted, but RFC 3934 doesn’t allow chairs to retaliate for that.”
“Presumably the chairs “forgot” to flip the censorship button off after 30 days. Oh, yes, I’m sure they’re so sorry for this accidental violation of the rules, a violation that just happens to prevent a new objection from showing up on list for other WG participants to consider during the limited-time last-call period. This has nothing to do with the NSA money. Move along now.”
LLMs & AI
Systems design 3: LLMs and the semantic revolution by Avery Pennarun
“Communication works best and most smoothly if you have a good listener and a clear speaker, sharing a language and context. But it can still bumble along successfully if you have a poor speaker with a great listener, or even a great speaker with a mediocre listener. Sometimes you have to say the same thing five ways before it gets across (wifi packet retransmits), or ask way too many clarifying questions, but if one side or the other is diligent enough, you can almost always make it work.”
“Web browsers are and have always been an epic instantiation of Postel’s Law. From the very beginning, they assumed that the server (content author) had absolutely no clue what they were doing and did their best to apply some kind of meaning on top, despite every indication that this was a lost cause. List items that never end? Sure. Tags you’ve never heard of? Whatever. Forgot some semicolons in your javascript? I’ll interpolate some. Partially overlapping italics and bold? Leave it to me. No indication what language or encoding the page is in? I’ll just guess.”
“LLMs aren’t going away. Really we should coin a term for this use case, call it “b2b AI” or something. For this use case, LLMs work. And they’re still getting better and the precision will improve with practice. For example, imagine asking an LLM to write a data translator in some conventional programming language, instead of asking it to directly translate a dataset on its own. We’re still at the beginning. But, this use case, which I predict is the big one, isn’t what we expected. We expected LLMs to write poetry or give strategic advice or whatever. We didn’t expect them to call APIs and immediately turn around and use what it learned to call other APIs.”
Roaming Charges: President Bone Spurs Fetes Crown Prince Bone Saws by Jeffrey St. Clair (CounterPunch)
“Martin Casado, a partner at the VC firm Andreessen Horowitz, a top investor in Silicon Valley, says 80% of the startups pitching to them are now using Chinese AI models: ‘I’d say 80% chance [they are] using a Chinese open-source model,’ says a partner at a16z.””
Why it takes months to tell if new AI models are good by Sean Goedecke
“[…] for people who engage in intellectually challenging pursuits, there’s an easy (if slow) way to evaluate model capability: just give it the problems you’re grappling with and see how it does. I often ask a strong agentic coding model to do a task I’m working on in parallel with my own efforts. If the model fails, it doesn’t slow me down much; if it succeeds, it catches something I don’t, or at least gives me a useful second opinion.
“The problem with this approach is that it takes a fair amount of time and effort to judge if a new model is any good, because you have to actually do the work: if you’re not engaging with the problem yourself, you will have no idea if the model’s solution is any good or not. So testing out a new model can be risky. If it’s no good, you’ve wasted a fair amount of time and effort! I’m currently trying to decide whether to invest this effort into testing out Gemini 3 Pro or GPT-5.1-Codex − right now I’m still using GPT-5-Codex for most tasks, or Claude Sonnet 4.5 on some simpler problems.”
“Each new model launch is watched to see if this is the end of the bubble, or if LLMs will continue to get more capable. The reason this debate never ends is that there’s no reliable way to tell if an AI model is good.”
“When you’re talking to someone who’s less smart than you, it’s very clear. You can see them failing to follow points you’re making, or they just straight up spend time visibly confused and contradicting themselves. But when you’re talking to someone smarter than you, it’s far from clear (to you) what’s going on. You can sometimes feel that you’re confused by what they say, but that doesn’t necessarily mean they’re smarter. It could be that they’re just talking nonsense. And smarter people won’t confuse you all the time − only when they fail to pitch their communication at your level.”
“[…] it’s hard to judge between two models that are both smarter than you (in a particular domain). If the models do keep getting better, we might expect it to feel like they’re plateauing, because once they get better than us we’ll stop seeing evidence of improvement.”
This is an interesting point of view. I’ll have to think about that. For me, the damned things keep being spectacularly wrong relatively quickly, at least for the work that I ask it to do.
So I was writing some notes in Zed the other day. I’m kicking its tires to see what it can do for me. It’s smooth and it’s fast. But does it do what I need?
Well, one thing that it does by default is to predict text while I’m typing. It’s irritating because I already know what I want to write.

It was the text below, if you want to try it:
You can do this with <a href=“https://learn.microsoft.com/en-us/aspnet/core/fundamentals/dependency-injection?view=aspnetcore-9.0#keyed-services”>keyed services</a> (that page shows usage in ASP.NET; see also <a href=“https://learn.microsoft.com/en-us/dotnet/api/microsoft.extensions.dependencyinjection.servicecollectionserviceextensions.addkeyedsingleton?view=net-9.0-pp”>AddKeyedSingleton and <a href=“[cursor was here]”>GetRequiredKeyedService).
The suggestion, though, came in just as I was about to paste the URL in from the source. I was kind of surprised by it and was about to delighted by the time-savings…but it’s the wrong URL.
it’s tough to catch this difference, so I’ve highlighted it below.
https://learn.microsoft.com/en-us/dotnet/ api/microsoft.extensions.dependencyinjection. servicecollectionserviceextensions.getrequiredkeyedservice ?view=net-9.0-pp https://learn.microsoft.com/en-us/dotnet/ api/microsoft.extensions.dependencyinjection. serviceproviderkeyedserviceextensions.getrequiredkeyedservice ?view=net-9.0-pp
There is no way that the LLM is going to get this right. The pattern of the previous URL in the context is always going to outweigh whatever probability the right answer will have, if it’s in the training set at all. It’s always going to make a reasonable but incorrect suggestion. I just don’t see how it would get smarter about this without having the ability to quickly look these things up—as a well-trained researcher or writer would—and to know that it should do so because the “obvious” answer is wrong. LLMs are not going at detecting when things are wrong or when it doesn’t have enough information to make a valuable suggestion.
Now, this might be a reason to argue to change the URLs to make it easier for an LLM to guess correctly. I guess that’s one way to do it, and it’s not a bad thought to have, i.e., is my scheme more complicated than it needs to be?
But then you realize that the problem is not with your scheme. It uses the name of the class in the URL. That makes sense. The class’s name is also different from the first one for very good reasons.
Nothing pushes you to change this, dumb it down, or simplify it, other than a desire to have a tool do other work for you. This is like making french fries and pizza every day for dinner because your kid refuses to eat anything else. It’s like watching only superhero movies because kids don’t like anything else and don’t understand anything else.
Oh.
I get it now.
No wonder everyone is willing to dumb down the world to use LLMs.
This idea of simplifying something that’s more complicated than it needs to be isn’t per se a terrible idea. It’s similar to when you write documentation for an API and you notice that the API is more complicated than it needs to be. Just the act of documenting it helps you make it better. So, in this sense, thinking of a potentially dumb coworker helps you build a better product.
But it’s also kind of like baby-proofing your house when you don’t have a baby. It feels like being asked to accommodate the lowest common denominator where the bar is set as low as whoever happens to show up needs it to be set. This doesn’t excuse poor writing. That last sentence, for example, was a bit of a doozy, but I think you see my point. Are we going to be writing everything as if we’re explaining it to a five-year-old just so people on the mental level of five-year-olds can use machines to understand it?
When people would argue for simplifying things so that the LLM can understand it, it feels ridiculous because we are three years into having these tools and they still can’t get these answers right.
People are cheerfully accepting whatever results they get—the wrong URLs, the wrong data, the wrong numbers—everywhere. They don’t bother checking which model they’re using. Why would they? Why are we expected to know the difference between all of these weird code names?
And if I’d configured Zed to use a more powerful model, would it still be able to deliver results for something like code-completion in a timely manner? Or would I just be waiting around for my faithful helper to bring the stick back to me? Is that writing? Is that flow?
No, in all likelihood, I would just have had to wait longer for probably the wrong URL to have been filled in anyway.
Let’s just agree to use these tools for things that they do pretty well—like transcribing voice or translating text—and not for things that have to be precisely correct.
A little while later, I was writing a longer bit of text but, man, Zed, just keeps trying to make predictions. It’s a slick implementation—very fluid—but it is annoying because I’m writing over heah. Like, leave me alone. I don’t want predictive text for plain text. If you also don’t want that, then you’ll have to hunt through thousands of settings to figure out how to turn it off. Or, you can take this shortcut.
The setting is under Languages & Tools / Languages / Plain Text and is called Show Edit Predictions. You can see in the screenshot below that the setting is enabled and that there is a whole paragraph generated for me.
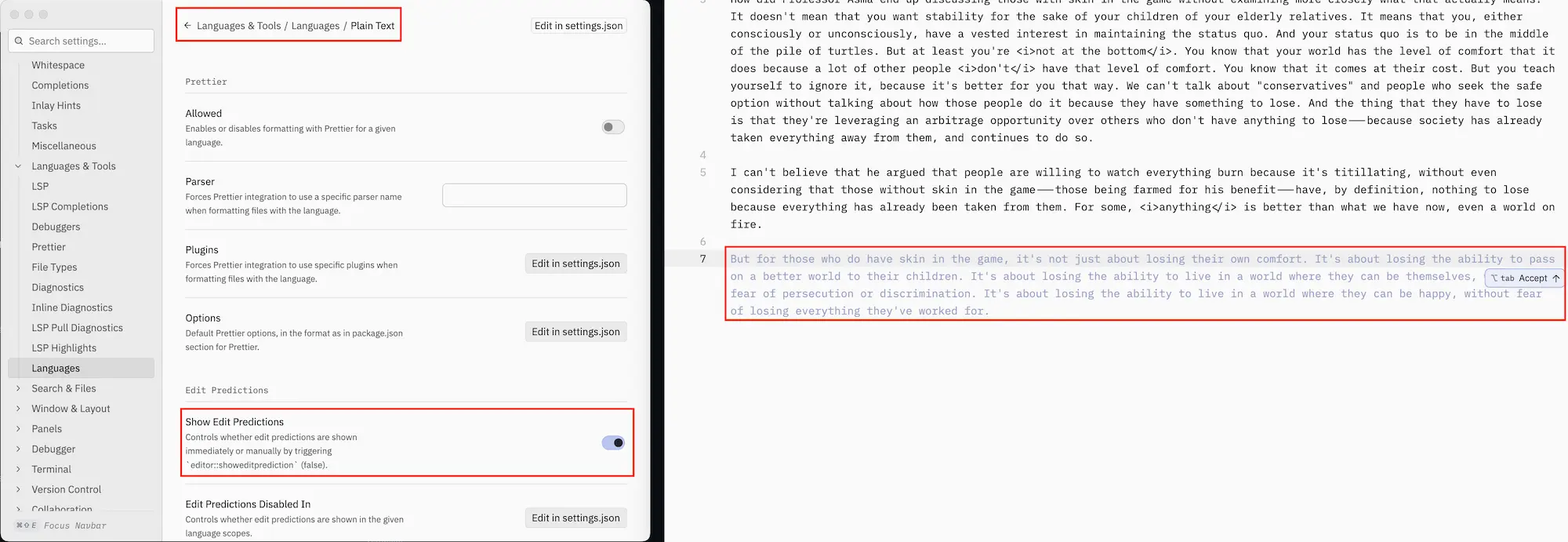 Zed's Edit Predictions are enabled for Plain Text by default
Zed's Edit Predictions are enabled for Plain Text by default
Look, I get it. Some people want the machine to do their writing for them. Me? I can’t stop writing anyway. I don’t need the machine’s help. Don’t even bother telling me that I could get higher-quality text if I were to choose a smarter model, or pay $200/month for a premium subscription. That just means that the prompt would be slower…because these things aren’t miracle workers.
And, even then, the text would probably be stupid, at least by my standards. I realize that I have high standards. I am just going to come out and say that a lot of people seem to be perfectly satisfied with generated text that is boring, stupid, and usually at least partly, if not entirely, wrong. I’m not here to discuss them or their deficiencies right now. I just don’t need a machine writing English text for me. By the time it’s done suggesting, I’m already way ahead of it.
So, let’s turn off that silly feature.
 Turn off edit predictions to be left in peace
Turn off edit predictions to be left in peace
Google tells employees it must double capacity every 6 months to meet AI demand by Benj Edwards (Ars Technica)
Already just the title suggests that something tediously stupid is happening.
“During an all-hands meeting earlier this month, Google’s AI infrastructure head Amin Vahdat told employees that the company must double its serving capacity every six months to meet demand for artificial intelligence services, reports CNBC. The comments show a rare look at what Google executives are telling its own employees internally. Vahdat, a vice president at Google Cloud, presented slides to its employees showing the company needs to scale “the next 1000x in 4-5 years.””
Jesus Christ, they really are huffing their own supply. You should be laughed out of the room for even suggesting that this is a realistic goal. Where do the supplies come from? Where does the power come from? Where do the chips and hardware come from? China? They’re like the only ones that can realistically do anything like this—and even they can’t do it. The U.S. is running on fumes and scams and wishes, so just give up on that idea.
Read some of the comments: the relatively well-informed technical audience of Ars Technica are nearly uniformly appalled at all of this shit. They’re all commenting there like Ed Zitron bots but it’s hard to disagree with most of what is said there.
“Google needs to be able to deliver this increase in capability, compute, and storage networking “for essentially the same cost and increasingly, the same power, the same energy level,” he told employees during the meeting. “It won’t be easy but through collaboration and co-design, we’re going to get there.””
Fairy tales, rainbows, and unicorns. This type of meeting is an all-hands that exhorts engineers to “nerd harder”.
And there’s still no money in this business. OpenAI is by far the largest. They claim 800M “weekly users” (whatever the fuck that means) but only about 3-4% of those users pay a single penny for the service. And OpenAI loses money on every query. So what’s their plan to convert those users to paying users? Do they even have one? Would it be realistic? Are people going to pay money to generate text snippets? Maybe. Most won’t.
This is how businesses used to grow: build a user base. The difference then was that the “free” service was essentially free to produce as well. So “freeloading” users didn’t cost the company money. Instead, they were farmed for their data. OpenAI does this with its free users as well but the cost of the service is astronomically higher than whatever meager returns they could earn by selling that data six ways to Sunday.
Meanwhile, here’s a Google employee who’s started whistling a different tune recently—after having spent the first couple of years publishing effusive and book-length essays on the wonders of LLMs—and whose latest post is Treat AI-Generated code as a draft by Addy Osmani (Elevate).
“Treat the AI’s output as untrusted input – it might be syntactically correct and even pass tests, but it hasn’t earned your trust until a human verifies it. AI models often produce plausible-looking but subtly flawed code, including hallucinated functions or insecure patterns [2]. So never merge code that hasn’t been read and understood by a human. As one engineer put it, blindly trusting AI output without verification risks immediate bugs and “systematically degrades our ability to catch these errors” because the very skills needed to validate code atrophy from disuse”
This is a joke, of course, because no-one does this. OK, some people do it, but they are a rounding error, and their dedication to doing it well degrades with time.
Saying that you’re going to review AI-generated output is just like saying that you’re going to stop smoking or that you’ll never trust an article or video without verifying the source. Everything you see and hear these days works by way of psychological levers to scam you into doing something that is beneficial to whomever is trying to trick you and nearly always detrimental to yourself.
You’re not going to eat healthier; you’re not going to stop doomscrolling; you’re not going to start exercising; you’re not going to read more books; and you’re sure as shit not going to review AI-generated output. Instead, you’re going to put your effort into figuring out some way that you can avoid responsibility when it inevitably blows up.
No-one is reviewing LLM-generated code. OK, fine some people are. They are a rounding error. The likelihood that they are carefully reviewing the code decreases each time they don’t find anything. The more they start skimming, the less likely they are to find errors, the better the code seems, and the less likely it is that they will carefully review the next batch of code. It’s a pathological cycle of doom.
Is it weird that people can’t just take the modest efficiency improvement offered by LLM-based tools? The tools generate code and text more quickly than most people can, but it needs review. The product is there, ready for review in 10% or 5% of the time that it would take the developer or writer to produce it. They should now spend time reviewing that output—say 50% of the time that they would have spent doing it themselves. They would still come out ahead! They’d be about 30-40% faster (let’s be generous).
But no-one wants to read all that output. Hell, most people probably can’t read it. That is, they can’t read it well enough to be able to judge whether it’s correct or not. Hell, if they knew that, they’d have written it themselves rather than having an LLM do it.
On the plus side, these people have a lot more free time for browsing AI-generated content on social media.
It’s Getting Harder And Harder To Preserve Our Mental Sovereignty by Caitlin Johnstone (Substack)
“[…] the ruling class is not pouring trillions of dollars into AI so that we can all have free Studio Ghibli-style illustrations of ourselves. There is an understanding that major returns on investment will come largely in the form of these new technologies being deliberately knit into every part of our civilization, driven by the official and unofficial power structures that we live under, and that this will happen in a way that benefits the rich and powerful.
“We’re on a trajectory where soon all our information will be stored and analyzed by artificial intelligence controlled by governments and billionaire megacorporations who can then use that information to surveil, manipulate and oppress us. All our medical and financial information. Whole psychological profiles based on what we view and say online. A far more thorough assessment of our personalities than we could ever create on our own.”
And even if they’re completely wrong, it won’t matter. They won’t be wrong. They will be the truth. Who you are and what you believe won’t matter. What matters will be what the data say about who you are and what you believe.
Programming
The 9 Cost Factors by Steve Francia (spf13) [of choosing a programming language]
“[…] language choice was mostly about whether a language could do the job. But today languages have matured to the point where many languages could accomplish most tasks, the question isn’t “could” but “is the right choice considering all the economic factors”.
“The choice of language determines how expensive the job will be, how long it will take, and how reliable the result will be. Language choice has become a deeply strategic decision, one that requires moving the conversation from preference to performance, from opinion to economics.
“We need a framework that makes invisible costs visible and ensures we’re evaluating what actually determines success: not which language your team prefers, but which language your business can afford.”
“Refactoring Safety: How confidently can you modify existing code? Static typing provides a safety net for changes. Dynamic languages can make small changes quick but at the expense of increased risk. Quality IDE tooling with reliable refactoring support dramatically reduces the cost of evolving a codebase.”
“Profiling & Debugging Tooling: The quality of debuggers and profilers directly impacts the time it takes to solve problems. Mature ecosystems like Java and Go offer excellent tooling, while newer languages can leave developers struggling.”
“Testing Infrastructure & Readability: How easy is it to write and maintain tests? A language with robust testing support, clear error messages, and inherent readability is far cheaper to maintain when the original author is gone.”
“Readability and Cognitive Load: The factors that make code easier for humans to understand (covered in Authoring Cost) matter doubly for LLMs. Simple, explicit syntax with minimal “magic” helps AI assistants generate correct code. Heavy metaprogramming, implicit behaviors, and complex abstractions confuse AI models just as they confuse human developers.”
I guess the advice is to write for untrained developers. One person’s good code is everybody else’s too-clever code. Address inherent complexity while avoiding accidental complexity. It’s as simple as that. 🙃
- Initial Velocity vs. Sustained Velocity
- Readability and Cognitive Load
- Refactoring Safety
- Ecosystem Maturity
- Module Systems and Interface Definitions
- Concurrent Development Support
- Documentation and Knowledge Transfer
- Complexity Management
- Dependency management at scale
- Talent Pool Size
- Learning Curve
- Community Resources
- Profiling & Debugging Tooling
- Backward Compatibility & LTS
- Testing Infrastructure & Readability
- Type System
- Performance & Efficiency
- Serverless Suitability
- Hardware Needs
- Build/CI Speed
- Artifact Complexity
- Open Source Footprint
- API Consistency
- Stability and Churn
- Readability and Cognitive Load
- Context Window Limitations
- Foreign Function Interface (FFI)
- Data Exchange Formats
- Ecosystem Integration
- Memory Safety
- Package Manager & Supply Chain Risk
- Integrated Tooling
- Dependency on C Libraries
The Inconceivable Types of Rust: How to Make Self-Borrows Safe (Considerations on Codecrafting)
“[…] when I say something can’t be done in Rust, what I mean is that it can’t be done in a safe, zero-cost way. As an army of internet commenters are no doubt rushing to observe, any limitation of a static type system can be bypassed by using unsafety or runtime checks instead (e.g. “lol, just wrap everything in Arc<Mutex<T>>” or “lol, just build your own memory management on top of Vec indices”). And the fact that a less safe or efficient workaround exists is of great interest to people who just need to solve a problem quickly. But from a language design perspective, the pertinent fact is that Rust’s type system has gaps which make certain common tasks impossible to do in a way that lets Rust be Rust, and not just a glorified C or Javascript.”
“I think async functions (and closures) should be desugared into 100% safe Rust code that the user could have written themselves if they wanted to. Not because users would necessary actually want to do that very often, but because having a desugared version of every magic feature is useful didactically and for low-level libraries, and because it forces Rust to be honest about its type system instead of papering over the cracks with compiler magic.”
C# has been doing that for many versions now. Each version introduces language features that allow more of the code in the runtime to be expressed in highly performant C#.
“Rust made the interesting design decision to require explicit type annotations on every function boundary and every custom type, and yet also make it impossible to write explicit types in many cases. This was already a problem in Rust 1.0 with closures, but got much worse a few years later with the introduction of async Rust andimpl Trait.”
“This syntax is more verbose than the current syntax, but I don’t expect users to actually use named lifetime syntax that often. I see it likedrop. You can write all yourdropsexplicitly if you want to, but most of the time people let the compiler insert them implicitly instead. Likewise under my proposal, people will usually still use the current syntax and let the compiler implicitly insert anonymous lifetimes, but they can also write named lifetimes explicitly if they want to.”
“However, they are still a problem forasyncfunctions because we need to be able to specify the types of local variables as well. Consider the following code:”“What is the type ofasync fn foo() { let ms = MyStrings::default(); drop(ms.x); // What is ms's type here?!?! sub().await; drop(ms.y); }msat the await point? The formal type system would answer “oh, the type isMyStrings, that doesn’t change.” However, its de-facto type clearly does change. After all, you can’t access thexfield on it like you could for any true value of typeMyStrings. The true type is now something else entirely, an inconceivable type.”
“Consider the following code:”async fn foo() { let mut s = "Hello, world".to_string(); let r = &mut s; // What is the type of s here??? sub().await; r.push('!'); println!("{}", s); }“What is the type of
sat the await point? Again, the formal type system says “it’sStringthe whole time, that doesn’t change”, but again that’s a lie. The de-facto type ofscan’t beString, because it doesn’t support the operations of a value of typeString. In fact, it doesn’t support any operations, because any attempt to accesssat that point will result in a compile error.“Therefore, the type of
smust be temporarily changing to some other, inconceivable type. Specifically, the types of borrowed values are inconceivable types.”
“[…] borrow checking is the inevitable consequence of protecting against aliasing bugs, regardless of which memory management strategy a language uses.”
That reminds me of A comparison of Rust’s borrow checker to the one in C# (em-tg)
“Here’s my theory: C# already had an equivalent to all of these things in its “unsafe” subset, so when introduced,ref-safety changes were typically framed as “bringing the performance of safe code closer to that of unsafe code,” which is arguably the opposite perspective of Rust’s “bringing the safety of high-performance code closer to that of high-level languages.” Perhaps that framing makes people miss that although the two languages are pushing in opposite directions, they might actually be getting closer together.”
“scoped refis a new reference type which promises to never return the reference or assign it to an output parameter. In Rust terms, each C# function really has two lifetimes associated with it, “caller-context” and “function-member”, with the latter used forscoped refand the implicitref this[…] Just like we can “scope” arefparameter, we can “unscope” the implicitref thiswith the[UnscopedRef]attribute.”
“Besides splitting access by space, you can also split access by time.
“Specifically, you can create a second copy of the reference as long as one copy can only be accessed before a given time, and the other copy can only be accessed after a given time. Since the access is split into disjoint periods of time, this is still sound.”
“This is the essence of borrow checking. It’s not some arcane, low level memory management strategy, but just a natural, essential method of statically reasoning about aliasing in your code.”life 'a; let v = vec![42]; // v has exclusive access to the object let r = &'a mut v; // r has exclusive access to the object before time a // v has exclusive access to the object *after* time a
“There are two ways to consider a type system. The first is what your code does, in an abstract machine, with no concerns about how it is actually implemented. I call this “the value level”.
“The second level is how your code does it, in terms of low level implementation details like how values are stored in memory, which I call “the bytes level”. In a high level language, this might not even be exposed to users, but as Rust is a systems language, it gives programmers control over low level details like this.”
“The whole point of a destructor is to destruct your type. The value is disassembled and the type goes away. You start withTand end with nothing. However,Droptakes&mut Tinstead, which has the postcondition that everything is unchanged and yourTis still sitting there, good as always. Somehow, Rust ended up with a destructor api that can’t actually destruct anything.”
“In Rust, there is no way to transfer ownership of a value without moving the value. This was a major problem when Rust addedasyncand decided that it needed to deal with non-movable types after all. Since the assumption of movability is built into the language in such a core way, there was no way to add non-movable types other than just saying “ok, everything related to them isunsafe, but here’sPinso you can at least partially hide the unsafety from your users, have fun”.”
“Currently in Rust, you always have to move values when converting between different base types. E.g. even just wrapping a value in a newtype (or unwrapping it) requires moving the value. However, the “move and reconstruct” paradigm won’t work here because our enum variants may contain non-movable types. Therefore, we need a way to convert between the different state types in-place.
“Therefore, we need to add three things to Rust:”
- A way to specify that different types have the same memory layout
- A way to specify that certain fields have the same location within the type for different types
- The type system understands this and allows safe transmutes between them.
- Allow updating enums in a way that is aware of this.
“This post is already very long, and non-forgettable types would add much more complexity than anything I’ve covered, since it violates a more central assumption of the language than even non-movable types do. Therefore, for the sake of keeping this proposal merely very long and minimizing the complexity of Rust as much as possible, I think it’s best to just punt on that subject and implement enum alias checking via special compiler magic rather than non-forgettable types.
“The “special compiler magic” approach has the downside that it will be impossible to factor parts of the poll method out into separate helper functions, because the required types won’t exist in the type system and hence can’t be named in the function signature, but I think that’s a small price to pay for leaving this can of worms unopened.”
“I hope that this post still helps people to think about the nature of the problem. In particular, it’s frustrating to see people say that self-borrows are an inherent impossibility with borrow checking when that limitation is really just a consequence of idiosyncratic choices made by Rust, and if not in current Rust, it certainly could have been supported in an alternate history Rust that made slightly different choices, and likely will be supported in future languages with borrow checking.”
I very much prefer these analyses of Rust—driving it forward to address some of its limitations—to the glazing that videos like Misusing Macros for fn and Profit (Live @EuroRust ‘25!) by No Boilerplate (YouTube) give Rust, never once mentioning how slow the compiler is, or how convoluted the syntax gets when you’re trying to do some relatively straightforward things.
I’ve never heard No Boilerplate complain that async is difficult, probably because he doesn’t see the point of using it, probably for the same reasons that he shits on Python programmers and anyone who uses a non-console-based IDE.
The humble and curious attitude of the author of the paper above is much preferred to the close-minded arrogance that Tris Oaten unfortunately seems to exude in the linked talk. I’ve never, ever thought that the tool and language I was using was the best of all possible worlds. I am constantly dissatisfied, constantly seeking to improve the language, the runtime, the libraries, and the tools.
Fizz Buzz with Cosines by Susam Pal
“[…] and s0(n) = n, s1(n)=Fizz, s2(n) = Buzz and s3(n)=FizzBuzz. A Python program to print the Fizz Buzz sequence based on this definition was presented earlier. That program can be written more succinctly as follows:”from math import cos, pi for n in range(1, 101): print([n, 'Fizz', 'Buzz', 'FizzBuzz'][round(11 / 15 + (2 / 3) * cos(2 * pi * n / 3) + (4 / 5) * (cos(2 * pi * n / 5) + cos(4 * pi * n / 5)))])“The keen-eyed might notice that the expression we have obtained for f(n) is a finite Fourier series. This is not surprising, since the output of a Fizz Buzz program depends only on n mod 15. Any function on a finite cyclic group can be written exactly as a finite Fourier expansion.
“We have taken a simple counting game and turned it into a trigonometric construction: a finite Fourier series with a constant term 11/15 and three cosine terms with coefficients 2/3, 4/5 and 4/5. None of this makes Fizz Buzz any easier, of course, but it does mean that every Fizz and Buzz now owes its existence to its Fourier coefficients.”
An Elm Primer: The missing chapter on JavaScript interop by Christian Ekrem
“Elm keeps that world at arm’s length. More ceremony and verbosity? Sure. But your app stays clean and pure.”
And why is cleanliness and purity worthwhile? It’s a means to an end: that end is to be able to define as much of your program’s logic in a way that all inputs and outputs are predictable, testable, and, in a sense, provable.
You want to separate nondeterministic—impure—parts of the application from the pure parts. The larger a pile of pure code you have, the better, because it can be tested and made bulletproof so that you don’t have to think about about it when a problem arises. It is pure logic and it is tested. It’s not the first place you look when your program has a bug.
You’re really trying to push potential bugs as far toward the boundaries of your application as possible so that you can search a much smaller solution space when something inevitably happens. The solution space is much less complex and the fix is hopefully easier to implement.
If you don’t find the bug there, then you might have to revisit your tests and ask yourself whether they actually guarantee that the bug that you’ve found can’t happen. If they don’t, then you write a test to verify the new case. Then you make that test green and you’ve fixed the bug. You’ve increased the amount of pure, tested logic. The next time a bug shows up, the likelihood that it will be in the pure code has gotten just a little bit smaller. That’s all programming is.
- Flags are your program’s initialization data
- Ports enable two-way communication with JavaScript
- Manual bootstrapping gives you control
“Elm treats JavaScript like any external system in Clean Architecture—useful for infrastructure concerns (clipboard, localStorage, analytics), but kept at arm’s length from your core logic. Your Elm code stays pure, predictable, and safe. The JavaScript world can throw exceptions and misbehave all it wants; your ports are the controlled boundary.
“For React developers, this might feel like extra ceremony compared to just importing an npm package. But that ceremony is precisely what keeps your app reliable. You’re not avoiding JavaScript—you’re just being intentional about where the boundaries are.
“With flags and ports in your toolkit, you have everything you need to build real applications.”
I followed a link to The Clipboard API: How Did We Get Here? by Christian Ekrem, which ended with this,
“Next time you see 1000 npm packages for something that “should be simple,” remember: it probably was simple, once. Then browsers happened. Then reality happened. Then we got 1000 slightly different solutions to the same accidental complexity.
“Welcome to web development in 2025, where copying text to the clipboard remains an unsolved problem.”
I’d just read another article Systems design 3: LLMs and the semantic revolution, which was similarly ignorant and dickish about open standards and their implementations.
Look: implementations aren’t perfect but the standards are well-thought out and a ton of the complexity comes from scamminess and security concerns surrounding a feature. “I just want to copy from the clipboard. WTF??!??” Yeah, buddy. You and everybody else. Even if we didn’t live in a system that actively encouraged people to steal from each other as a way of making a living—gotta climb that pile of skulls to get your nut—we would still have to make apps bulletproof to protect ourselves from the handful of sociopaths who would even bother to try to steal from others in our world of fully automated luxury communism.
So you can’t just grab the contents of the clipboard. And passkeys are going to be complicated. Quit’cher bitchin’.
Unraveling coordinate systems by stak on June 24, 2013 (StakTrace)
“OMTC stands for off-main-thread compositor, and is what allows you to pinch a page on Fennec and have it instantly zoom. What’s happening here is the painted page is transformed in OpenGL, without Gecko really knowing about what’s going on. Since Gecko isn’t repainting anything, this is super fast, and allows us to animate pinch-zoom at 60 frames per second (or close to it).”
“If all we did was take the LayoutDevicePixels and tell OpenGL to render them bigger by scaling it in hardware, you would end up with a very pixellated and blurry view of the page. In order to make it look good again, we have to go back to Gecko and tell it to repaint the visible area of the page at a higher density, allowing us to remove the OpenGL scaling. For example, instead of rendering a paragraph of text into a texture and scaling that up in OpenGL to display a single word really big, we can tell Gecko to just render that one word really big, and to use up the entire texture to do it.”
This post is a dozen years old but the inherent complexity that it discusses has not gone anywhere. There is so much logic going on when a browser seamlessly renders text on a screen, regardless of zoom-factor or operating system. I remember working on a rendering system in the 90s that started on Windows and that I ported to MacOS 9 and then OS X in the early 2000s.
It started out rendering to screen but I had to overhaul and abstract everything when we needed to support high-resolution printing. Welcome to logical-unit mapping modes and converting between them. That was a good base from which to build the cross-platform version. We ended up getting zooming in the on-screen renderer for free. The whole damned thing was in C++, which, like, I can’t even imagine doing these days. Young me was a real go-getter.
How to use Web Components, and why you'd want to by Kevin Powell | Michael Warren (YouTube)
Michael walks Kevin through replacing his hand-written form with custom validation logic with a web component. See the <form-group> component (GitHub) documentation and source code.
Quake Engine Indicators by Fabien Sanglard
“A turtle swims in the water while a tortoise walks on land.”
The article is about something completely different but a footnote mentioned this thing that I think I’ve heard before but wouldn’t have remembered if asked.
“Quake does not render polygons using directly a texture and a lightmap. Instead it combines these two into a “surface” which is then fed to the rasterizer. After being used surfaces are not discarded but cached because the next frame is likely to need the same surface again.
“The RAM indicator is here to warn when the engine evicts from the cache surfaces that were generated and cached on the same frame. This means the geometry of the map forces the engine to operate beyond its surface cache capacity. Under this condition, the renderer enters a catastrophic “death spiral” where it evicts surfaces that will be needed later in the frame. Needless to say the framerate suffers greatly.”
- 🆗 Ship Faster with .NET MAUI: Real-World Pitfalls and How to Nuke Them by dotnet | Paul Usher (YouTube)
A lot of the pitfalls he discusses are relatively general: resolution, distribution, deployment, staying up to date with security, etc.
Dude recommends
Console.WriteLine()as an important debugging tool. Ok, buddy. On the other hand, it’s nice to see someone who shows his whole setup in detail, which, even though some of his tools are outdated (e.g., he uses CodeRush!), is nice to see, especially if you really have no idea how to get started.He goes on to discussing app-store-related problems and how to overcome some of them, which is also quite helpful, as this is a part of the process that few people talk about. It’s not particularly enlightening but it’s good to discuss, as you can’t deploy an app without getting on app store.
Another pitfall is dealing with lifecycle changes and interruptions: is the app in the foreground? Is the device asleep? Is there network connectivity? Is the battery low? Is the app in sleep mode? When do you perform which initialization? Which expectations can you have about connectivity? Everything is asynchronous and the situation outside the app changes all the time. You have to watch all of the events and respond appropriately.
He advises using the emulator or simulator for a tighter feedback loop but there’s no way to avoid testing on a target device—or multiple target devices, as their behavior varies as well. He mentions that two recent Android devices (a Pixel and a Samsung) had different behavior in crucial areas affecting his apps.
- 🆗 Community Toolkit Roundup by dotnet | Gerald Versluis, SergioPedri, Michael Hawker (YouTube)
They spent some time touting the benefits of the toolkits.
- There is an introduction to improvements to the MVVM toolkit.
- There is also a toolkit for Aspire, which is interesting.
- Then there’s the Maui MVVM toolkit, which adds a bunch of media support.
- The Windows toolkit added a lot of fixes and controls for WinUI3.
They note that a lot of stuff incubates in the toolkits and is often migrated to the official libraries after a while.
- ⛔️ Architecting an AI-Powered Sales Dashboard with .NET MAUI and Azure OpenAI by dotnet | Shriram Sankaran (YouTube)
The app he discusses summarizes market data using AI. Did we all just choose to forget that AIs are not good at numbers? Did I miss the technology that we used to fix this problem? Remember “AIs are not good at numbers?” I do! When did we fix that?
Anyway, the UI looks decent and it’s completely cross-platform thanks to Maui. It uses SyncFusion’s controls as well as standard Maui controls. He spends quite a bit of time going over the features of his app. The AI is used to query the app data with a built-in chatbot.
When he finally gets to the code, his project is curiously not using CommunityToolkit.MVVM (all of the properties are implemented manually instead of source-generated. He eventually gets to more source but it’s not very illuminating. I can’t really recommend it.
- ✅ GitHub Actions DevOps Pipelines as Code using C# and Cake SDK by dotnet | Mattias Karlsson (YouTube)
Cake is a build system written in C# with a rich .NET API. Mattias did a bunch of live-coding. The Cake scripts might be useful for defining a bunch of stuff that we currently use Azure Pipeline Definitions for. he demonstrates how provider plugins enable high-level abstractions that make it much easier to specify a declarative pipeline. It’s all in C#, so you use a code editor like Rider, with code-completion, refactoring, etc.
You continue to use the YAML pipeline definition to set up the environment but everything else will be in the Cake file. This makes a lot of sense and could be quite powerful. Instead of using a bunch of pipeline nested templates that you can’t run or debug, you could have a NuGet package with common APIs for Cake. You can also test a bunch of the Cake script locally (unless you have some highly specific steps like signing with a key only available in the cloud or calling a tool that’s only available in the cloud. You can use standard C# to make these optional when testing locally, though.
- ✅ Building Rock-Solid Avalonia Apps A Guide to Headless Testing with AI Assistance by dotnet | Dong Bin (YouTube)
Whereas Avalonia and Maui both support iOS, Android, Windows, and MacOS targets, Avalonia also support Linux targets, including Linux running on embedded systems. The target that Dong addresses though is the headless mode, which is used for end-to-end UI testing. Avalonia’s rendering is completely decoupled from the platform, with the headless platform being just another target, like Windows or Mac.
God bless him for actually showing us how to write tests in the code editor. he’s using Rider on Windows. His code uses
ObservablePropertyfrom the Community Toolkit. This is a good demo.In an advanced demo, he shows how to use “screenshot” rendering, even in headless mode. He also shows how to test controls for performance, both in speed and memory-usage, which is very important for building controls for highly constrained environments like embedded systems.
He points out that headless testing won’t help you with testing native features, actual visual look-&-feel. Instead, you can use the Skia renderer to approximate tests like that.
Finally, he actually introduces a usage of AI that makes sense to me: helping to write all of the unit, integrated, headless, and render tests. He explains how the task is focused, verifiable, and already has a lot of context to keep the generated code on the right path.
- 🆗 One Question, One Answer: Designing Seamless AI Agents with C# by dotnet | Mark Miller (YouTube)
The presenter works on CodeRush for DevExpress. He uses CodeRush (I guess?) in dictation mode to build his calculator app, which, you know, is going to be something that the AI can easily build, as there are probably millions of examples in the training data. The generated code is horrifically defensive and not even close to what I would have made, or what I consider to be maintainable, but it’s fine for a prototype.
So, here we have another video that’s just showing how to program with an AI. He’s arguing for a workflow that stays in the code and is delivered via talking—because it’s 2-4 times faster than typing for most people and LLMs are very forgiving of extra words and filler words—so that you can avoid most of the pain points of working with the by-now “classic” AI-chat interface.
He talks about lot about how to optimize the context but I guess his tool does this?
- ✅ C# Features you need Habits you want by dotnet | Bill Wagner (YouTube)
He introduces an existing “magic 8-ball” program, demonstrating its functionality. He doesn’t show any tests, though. That does not stop him from refactoring the app to take advantage of “newer” C# features. I write it in quotes because, while some of the features he shows aren’t necessarily new, it’s good to have a video that shows how you should be upgrading your types when you touch old code, to take advantage of better type-checking, to convert potential runtime errors to compile-time errors.
- non-nullable references.
requiredandinitproperties.- The
fieldelement for properties, which is new to C# 14. - The
System.Threading.Locktype instead ofSystem.Object, which allows the compiler to generate more efficient code, all without any change in behavior of the application. - Using verbatim strings and the newer multi-line verbatim strings.
- Collection expressions. (He explains how the compiler can optimize the capacity for a collection expression, where it cannot for a direct instantiation of
new List<T>().) - The spread operator. (He uses this to replace the explicit call to
ToArray(). Again, it’s easier to read and the compiler has more optimization opportunities.) - The
withkeyword. (He explains how this allows you to more easily work with immutable types and structures.) - Using a
readonly struct(This sets immutability, which also allows much better optimization, such as lowering copying/allocation when passing data through function/stack boundaries.)He optimizes his pattern-matching, where the compiler helps a lot to figure out exactly how much information is needed in the pattern. If a case can’t be reached, it’s an error. He removes the lower-bound check on several cases because they’re not needed. If you remove too much, the compiler tells you.
AnswerType type = randomIndex switch { >= 0 and <= 5 => AnswerType.Affirmation, >= 6 and <= 9 => AnswerType.Encouraging, >= 10 and <= 13 => AnswerType.Uncertain, >= 14 and <= 16 => AnswerType. Doubtful, >= 17 and <= 18 => AnswerType.Rejection, 19 => AnswerType.Redo, _ => AnswerType.Uncertain };The following is equivalent:
AnswerType type = randomIndex switch { <= 5 => AnswerType.Affirmation, <= 9 => AnswerType.Encouraging, <= 13 => AnswerType.Uncertain, <= 16 => AnswerType. Doubtful, <= 18 => AnswerType.Rejection, 19 => AnswerType.Redo, _ => AnswerType.Uncertain };If you were to change the order of the cases, putting the
<= 13case at the top, the compiler warns that the<= 5and<= 9cases will never be matched.AnswerType type = randomIndex switch { <= 13 => AnswerType.Uncertain, <= 5 => AnswerType.Affirmation, // Compile error. <= 9 => AnswerType.Encouraging, // Compile error. <= 16 => AnswerType. Doubtful, <= 18 => AnswerType.Rejection, 19 => AnswerType.Redo, _ => AnswerType.Uncertain };
- ✅ Smatterings of F# by dotnet | Matthew Watt (YouTube)
The first five minutes is an introduction to the programmer himself, which was a bit odd but it’s fine. It just might not be very interesting if you’re looking for technical guidance.
He moves on to an introduction to his blog, which he wrote with F# on the back-end, and React for the front-end. The comments section that he built uses Elmish, which is a library for emulating the highly functional Elm pattern of building code. The whole web site is functional from top to bottom so it’s kind of neat to see how that works for a real-world application.
He finishes up with five minutes on contributing to open-source code. Again, a nice touch.
- ✅ Overcoming the limitations when using AI by dotnet | Michael Washington (YouTube)
This guy doesn’t show up on the video. His voiceover and cadence is somewhat odd. It sounds very much like a text-to-speech engine. The whole presentation seems fake but the information is quite interesting. I guess he wrote the presentation but then had a machine read it for him.
He discusses how LLMs are bad at math, so the solution was to have the LLM create code to calculate answers. It’s wild how much f@&king processing power we’re willing to invest in getting the correct answer to 43 × 34. The LLM interprets the text, then generates an answer that includes a little Python program that it then executes in a sandbox so that i can include the output in its answer. It’s just flat-out nuts. Still, he shows off how he’s managed to work around these limitations but they are really elaborate.
Next up is that “AIs can’t write fiction”. He discusses AI story-builders, which use text-file databases in order to maintain context and continuity for stories. He found that page-by-page and chapter-by-chapter doesn’t work very well, but that paragraph-by-paragraph is the level of granularity at which an LLM needs guidance. There is a whole program surrounding the LLM’s inputs and outputs. Without it, the story goes off the rails immediately.
After that, he shows that AI cannot create applications. They can code but they have no idea of architecture and no idea how to deal with complex systems.
Find his slides and work at Overcoming limitations When Using AI.
Everyday Design by Niko Heikkilä
“[…] instead of thinking through the following steps:”
- Ask the user for the first input, and store it.
- Ask the user for the second input, and store it.
- Compare the inputs.
- If the first input is bigger, print “The first value is bigger”.
- If the second input is bigger, print “The second value is bigger”.
- If the inputs are equal, print “The values are equal”.
“You must turn it upside down:
“For all numbers
(a, b), the following behaviour is valid:”
- Given
a > b, return “The first value is bigger”.- Given
a < b, return “The second value is bigger”.- Given
a = b, return “The values are equal”.
“[…] if you conflate behaviour with verbatim instructions, infrastructure decisions suddenly dictate your design. Instructions do not equal behaviour.
“What matters is how declaring the behaviour makes you think of test cases instead of instructions, empowering you to start writing the tests immediately.”
I received a question about using an IOC container the other day, about,
“[s]omething a colleague coined as “Severaltons”, that’s to say singletons with more than one instance. Think of an espresso machine; it has two group heads on it, neither is transient, nor singular. […]
“My answer here is that […] I would just call it a transient and make sure the lifetimes work out in my app. So, the espresso machine would be a singleton, and it would consume two transient group heads. It would then just make sure that those suckers stay alive.
“But I hope you can see why a rustacean like myself finds this answer insufficient. So I’d love your opinion here.”
You can do this with keyed services (that page shows usage in ASP.NET; see also AddKeyedSingleton and GetRequiredKeyedService). This lets you register multiple instances with the same interface but differentiated by a key. At the injection site in the constructor, you have to use an attribute to indicate which key the IOC should use to select the instance matching the interface type of the parameter.
This is fine, I guess, but I’ve never used them. Why not? I never got used to it because the IOC Container that I used for the longest time didn’t support them. Instead, I kind of like using C# types for this instead of using DI Magic (as [our mutual colleague] would call it—and he’s not wrong).
I really like to use the IOC Container only for stuff that it absolutely must do and leave everything else in my code:
- Enforce singleton rule.
- Create instances and inject them into constructors.
Anything else?
Not really. I use marker interfaces or a factory for everything else.
For example, while I could use keys to register two instances, as shown below,
Services.AddKeyedSingleton<IGroupHead, GroupHead>(“left”)Services.AddKeyedSingleton<IGroupHead, GroupHead>(“right”)
I would have probably just used marker interfaces like this:
Class GroupHead extends IGroupHead, ILeftGroupHead, IRightGroupHead { }And registered like this:
Services.AddSingleton<ILeftGroupHead, GroupHead>()Services.AddSingleton<IRightGroupHead, GroupHead>()
This anchors the “severalness” in the type-system and doesn’t depend on any magic. There will only ever be two of these.
The first solution I thought of was to inject a factory that creates group heads and then created two of them in the constructor of the espresso machine, but this solution doesn’t even need a factory.
It takes a little practice to remember to enforce the boundary between your types, your logic, and the IOC. I generally keep it on a short leash.
A couple of days later, I saw this 45-second video, advising how to use keyed services.
Keyed Services are awesome in .NET by Nick Chapsas (YouTube)
The video demonstrates how to use keyed services, including the ugly attribute in the constructor to indicate the key to use to look up the correct instance to inject.
I wrote the following comment:
Man, I think it would be simpler and cleaner to just use marker interfaces, like IEmailNotificationService and ISmsNotificationService. That anchors the design in the type system instead of using DI magic.
How good engineers write bad code at big companies by Sean Goedecke
“I think the main reason is that big companies are full of engineers working outside their area of expertise. The average big tech employee stays for only a year or two1. In fact, big tech compensation packages are typically designed to put a four-year cap on engineer tenure: after four years, the initial share grant is fully vested, causing engineers to take what can be a 50% pay cut. Companies do extend temporary yearly refreshes, but it obviously incentivizes engineers to go find another job where they don’t have to wonder if they’re going to get the other half of their compensation each year.
“If you count internal mobility, it’s even worse. The longest I have ever stayed on a single team or codebase was three years, near the start of my career. I expect to be re-orged at least every year, and often much more frequently.”
That’s just a pathologically terrible way to run things. It is probably optimally profitable but it is gruesome and offensive. It is anti-human. It is anti-worker.
“[…] if you’re doing this, then of course you’re going to produce some genuinely bad code. That’s what happens when you ask engineers to rush out work on systems they’re unfamiliar with.”
That article referenced What you need to know about Performance Improvement Plans (PIPs) (Reddit), which you should only read if you still have the stomach to hear about how pathological and anti-human the environment is at large companies.
“A PIP is a formal document informing an employee about recurring performance issues. A PIP (Performance Improvement Plan) indicates that the employee is not meeting expectations for their job, and without an improvement, they’ll be let go.
“As the name implies, the PIP will outline a plan to improve your performance. This will almost always be based on time: deliver a feature, project, or milestone by a certain deadline (generally 1-3 months).
“Human Resources (HR) will be looped in, and they will likely attend the PIP kickoff meeting. As a general heuristic, HR involvement is almost always a bad sign. The job of HR is to protect the company, not to protect you.”
“Your manager felt your performance was weak enough that they literally spent hours documenting how you fell behind, and then informed you in a legal manner.”
Everything done with a minimum of human contact and association. Nowadays, the manager can just have an AI bang out a document for them.
Fun
Man Who Thought Fleetwood Mac’s ‘The Chain’ Was Over In For Thrill Of His Fucking Life (The Onion)
“Prematurely assuming he had reached the end of the 1977 rock masterpiece, local man Peter Verran, who thought Fleetwood Mac’s “The Chain” was over, was reportedly in for the thrill of his fucking life Monday. According to eyewitnesses, Verran incorrectly understood the receding guitar licks and cymbal crashes just before the three-minute mark to be the song’s conclusion, and was unaware that a suddenly resurgent bass line would soon escort him on the single most exhilarating sonic journey he would experience in the entirety of his time on earth.”
The Complex Contradictions of Chindogu: The Japanese Art of Useless Inventions by Today I Found Out (YouTube)
This is a nice ~9-minute video about Chindōgu, an art-style/social-critique invented by Kenji Kawakami, who seems like a stand-up guy. What qualifies an object as Chindōgu? From Chindōgu, it
- cannot be for real use,
- must exist,
- must have a spirit of anarchy,
- is a tool for everyday life,
- is not a tradeable commodity,
- must not have been created for purposes of humour alone: humour is merely the by-product
- is not propaganda,
- is not taboo,
- cannot be patented, and
- is without prejudice.
“Despite the pure and innocent aspirations of the art form, several Chindōgu managed to cross over to the commercial market, including two-sided slippers—currently sold in stores across Japan—and the selfie-stick, whose inventor, engaging their creation’s usefulness, apparently underestimated the depths of human vanity.
“These perversions of the form are an endless frustration for Kawakami who, despite the worldwide interest in his work and the popularity of books featuring his creations, has made almost no money from his more than 600 inventions, donating nearly all proceeds to his favorite charities.”
“I’ve never registered a patent and I never will, because the world of patents is dirty, full of greed, and competition. Things that should belong to everyone are patented and turned into private property. I made little money from the inventions. I did the photos myself, so I had to find models and pay for the printing and packaging. But, I’d like to make more, and set up a foundation to rid the world of land mines. Look at how the big powers create weapons that hurt little innocent people. I hate that.”
“Kawakami remains hopeful that Chindōgu will continue to empower people to resist rampant consumerism and unlock their inner creative potential.”“I think my things show us our stupid obsession in Japan and America with making life as easy as we can. With a new thing everybody has the ability to create, we just have to free our imaginations. The problem is that this society destroys our ability to think. We have to get this ability back. If people laugh, that’s fine. We need more of it. I believe in rejecting society by laughing at it.”
Light strands do not follow the laws of physics. I don’t care what actual physicists and mathematicians and topologists say. The strand of lights will go through an extra dimension just to make a knot in the middle of 20 feet of cord to spite you.
And when the strands get cold? Don’t get me started.
It’s like, it starts with “what did I ever do to offend you, dear light strand?”, proceeds quickly to “why have all my Gods forsaken me?” and, finally, to “cursing richly and thoroughly in several languages simultaneously” as if that will help anything but then, with divorce imminent, it mysteriously does, and you are at peace with the world because the strands have returned from their jaunt through n-dimensional spacetime and decided to straighten up and fly right.
The once ominously imminent, bordering on inevitable, prospect of a light-strand-precipitated divorce recedes, fading like a bad dream for one more year.